TOON — это ещё один способ записать те же самые JSON-данные, но компактнее и понятнее для моделей. Вместо "key": "value" он использует отступы как YAML и табличную запись для массивов объектов: шапка с названиями полей, дальше строки с данными.
Пример из README: вместо обычного JSON с пользователями — строка users[2]{id,name,role}: и две строки 1,Alice,admin и 2,Bob,user. Структура при этом не теряется: объекты, массивы и примитивы остаются теми же, формат — просто «другая запись» того же JSON.
Главная идея — экономия токенов и более предсказуемое поведение LLM на больших массивах данных. Помните, мы даже рассказывали про то, что от формата напрямую может зависеть результат генерации.
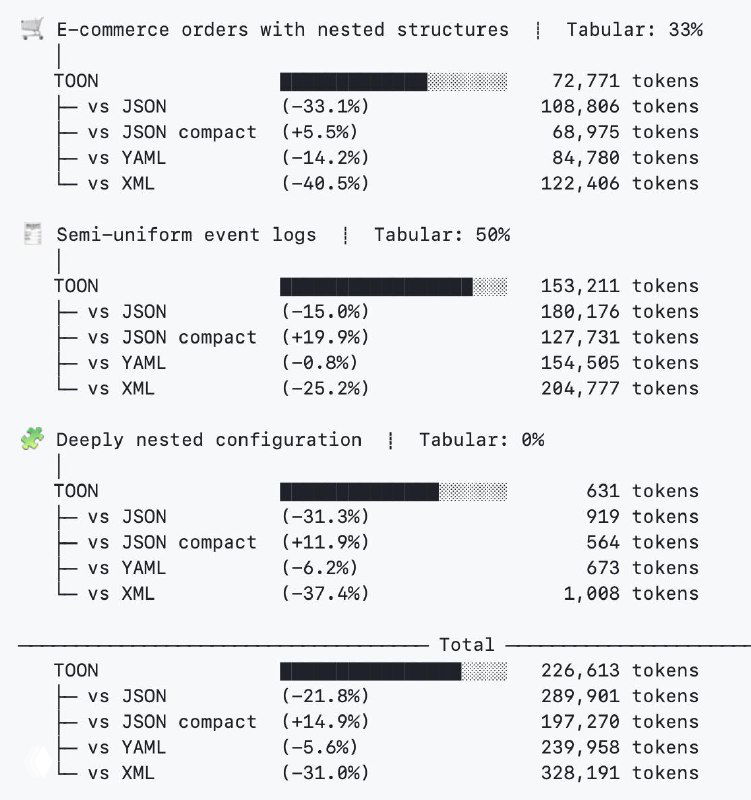
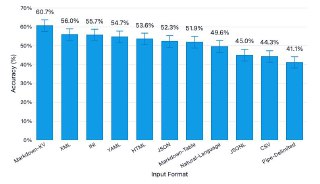
В бенчмарках TOON даёт порядка 30–60% экономии токенов на больших ровных массивах объектов по сравнению с форматированным JSON и заметно меньше, но всё равно ощутимо — против compact JSON. На ряде задач TOON показывает чуть более высокую точность ответов, чем обычный JSON при меньшем числе токенов.
При этом авторы честно фиксируют зоны, где TOON не выгоден.
Если структура сильно вложенная, неравномерная и почти не подходит под табличный вид, компактный JSON в тестах иногда оказывается короче. Если данные вообще чисто табличные и плоские, CSV по-прежнему даёт минимальный размер, а TOON добавляет небольшой оверхед ради явной структуры и валидации.
То есть формат заточен именно под «много однотипных объектов с примитивными полями», а не под любые данные подряд.
Для использования уже есть CLI через npx @toon-format/cli и TypeScript-библиотека @toon-format/toon.
@ai_for_devs