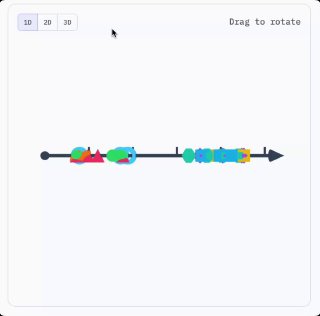
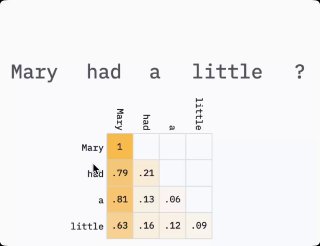
Подготовили перевод просто пушечной статьи про кэширование промтов. Внутри много теоретической базы изложенной простыми словами, с классными примерами и наглядными анимациями (без математики тоже не обошлось 🫠).
Вот как сам автор описал свою статью и мы с ним полностью согласны:
Не удовлетворившись ответами в документации вендоров ПО для разработчиков, которые хорошо объясняют, как пользоваться кэшированием промптов, но аккуратно обходят вопрос о том, что именно кэшируется, я решил копнуть глубже.
Я нырнул в кроличью нору устройства LLM, пока не понял, какие именно данные провайдеры кэшируют, для чего они используются и как это делает всё быстрее и дешевле для всех.
К концу этой статьи вы:
- глубже поймёте, как работают LLM
- сформируете новую интуицию о том, почему LLM устроены именно так
- разберётесь, какие именно нули и единицы кэшируются и как это снижает стоимость ваших запросов к LLM
📚 Читайте и комментируйте на Хабр.
@ai_for_devs
![Визуализация массива чисел «[75, 305, 284, 887]» — пример представления токенов и эмбеддингов в статье о кэшировании промптов](https://media-cdn.tgpages.com/imported-ai_for_devs-223-media-m-1770383912400-geau3z.jpg)