Все уже знают, что от промпта и контекста зависит буквально всё — от точности до адекватности ответа. Но вот вопрос: а влияет ли на результат формат, в котором вы общаетесь с LLM? Как оказалось — ещё как!
Разница в точности между форматами может достигать 16 процентных пунктов. То есть выбор между CSV, JSON или Markdown — это не мелочь, а реальный фактор, который решает, поймёт ли модель ваши данные и насколько хорошо.
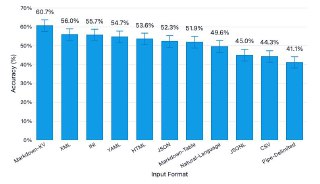
Исследователи прогнали через GPT-4.1-nano 11 популярных форматов — от JSON и YAML до HTML и Markdown-таблиц. Модель должна была отвечать на вопросы по данным о тысячах «сотрудников». И знаете что? Лучше всех справился формат Markdown-KV (ключ-значение: name: Alice), выдав 60,7% точности. А вот привычный CSV уныло замыкал таблицу с 44,3%.
Чем богаче контекст и структура, тем легче LLM понять, что к чему. Но — за всё приходится платить. Тот же Markdown-KV «съедает» в 2,7 раза больше токенов, чем CSV. То есть точность растёт, а чек за inference — вместе с ней. Вечная дилемма: либо дешево, либо круто)
Итого:
- Хотите максимум точности — берите Markdown-KV.
- Нужен баланс читаемости и цены — Markdown-таблицы.
- Используете CSV или JSONL по умолчанию? Возможно, прямо сейчас теряете проценты качества на ровном месте.
@ai_for_devs