ℹ️ Обычно для загрузки CSV в Pandas используют стандартную команду:
import pandas as pd
df = pd.read_csv("large_file.csv") Но если файл очень большой (гигабайты данных), этот способ может работать медленно и потреблять много памяти. Давайте ускорим процесс!
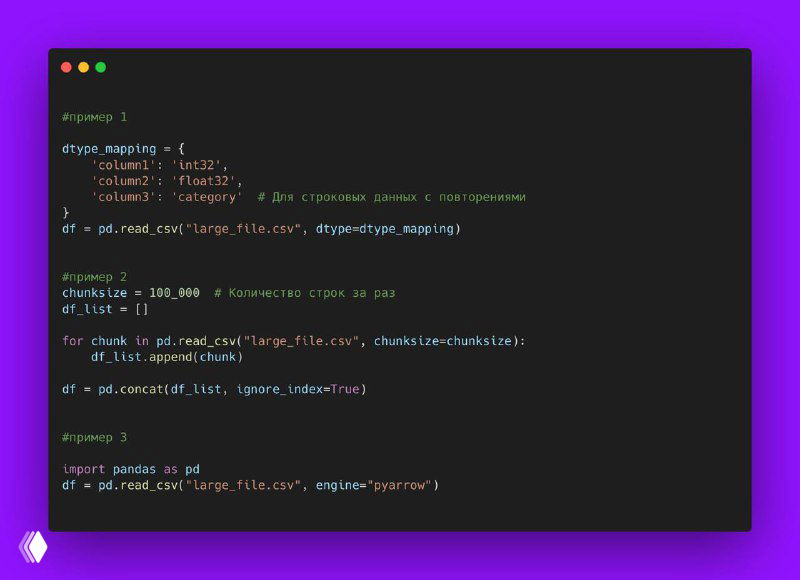
1. Используем dtype для уменьшения потребления памяти
Pandas по умолчанию пытается угадать тип данных, но это медленно. Лучше указать их вручную:
dtype_mapping = { 'column1': 'int32', 'column2': 'float32', 'column3': 'category' # Для строковых данных с повторениями } df = pd.read_csv("large_file.csv", dtype=dtype_mapping)❔ Экономия: уменьшается потребление памяти за счёт меньших типов данных.
2. Читаем CSV порциями (chunking)
Вместо загрузки всего файла разом, читаем его по частям:
chunksize = 100_000 # Количество строк за раз df_list = [] for chunk in pd.read_csv("large_file.csv", chunksize=chunksize): df_list.append(chunk) df = pd.concat(df_list, ignore_index=True)❔ Плюсы: загружается быстрее и не переполняет оперативную память.
3. Используем PyArrow или Polars для супербыстрого чтения
Pandas использует
numpy, но можно ускорить загрузку с помощьюpyarrow:import pandas as pd df = pd.read_csv("large_file.csv", engine="pyarrow")А если нужен максимальный перфоманс – попробуйте
Polars:import polars as pl df = pl.read_csv("large_file.csv")✔️ Polars быстрее Pandas в разы при обработке больших файлов!
tags: #полезно #разработка #python
🧭 @recura_tech