👁 Когда данные, с которыми работает программа, начинают превышать доступную оперативную память, обычный pandas может работать медленно и вызывать проблемы с производительностью. Для таких случаев можно использовать dask — библиотеку, которая позволяет работать с большими объемами данных параллельно и эффективно.
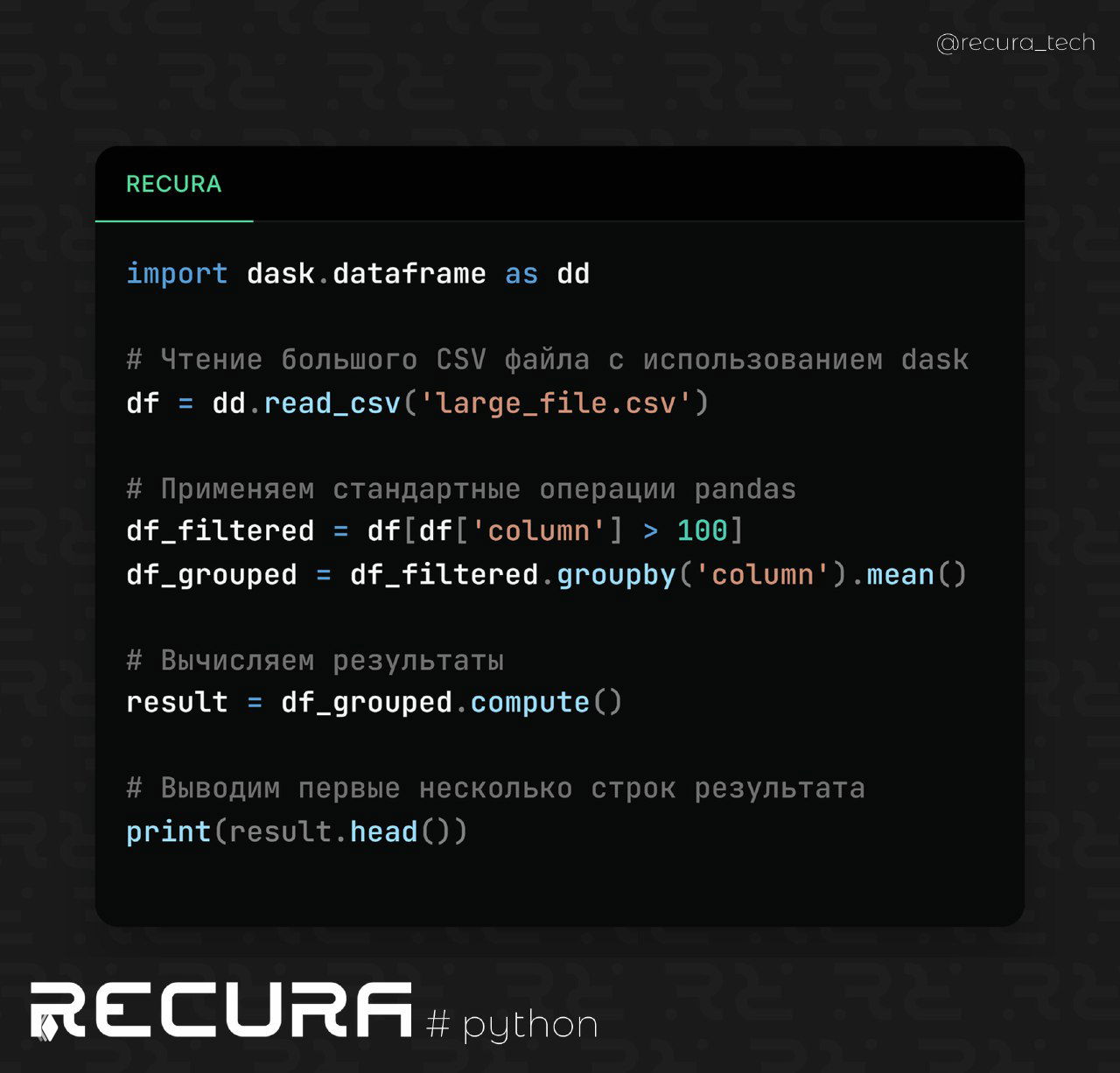
📝 Пример использования dask для обработки больших файлов:
import dask.dataframe as dd
# Чтение большого CSV файла с использованием dask
df = dd.read_csv('large_file.csv')
# Применяем стандартные операции pandas
df_filtered = df[df['column'] > 100]
df_grouped = df_filtered.groupby('column').mean()
# Вычисляем результаты
result = df_grouped.compute()
# Выводим первые несколько строк результата
print(result.head())
📌 Как это работает:
dask.dataframeиспользует так называемое ленивое выполнение, что означает, что данные не загружаются в память сразу, а операция выполняется только после вызова.compute().- Работа с большим объемом данных осуществляется с использованием распределенной обработки, что позволяет параллельно обрабатывать данные, ускоряя работу.
- При этом
daskсохраняет совместимость с APIpandas, так что миграция между этими библиотеками происходит без значительных изменений в коде.
❗️ Использование dask позволяет ускорить обработку и сэкономить ресурсы, что особенно важно при работе с данными на сервере или в облаке.
tags: #python #разработка