👁 Работа с большими CSV-файлами может занять много времени, если это делать вручную. С помощью Python можно автоматизировать этот процесс. Библиотека pandas идеально подходит для манипуляций с таблицами и позволяет легко загружать, обрабатывать и сохранять данные.
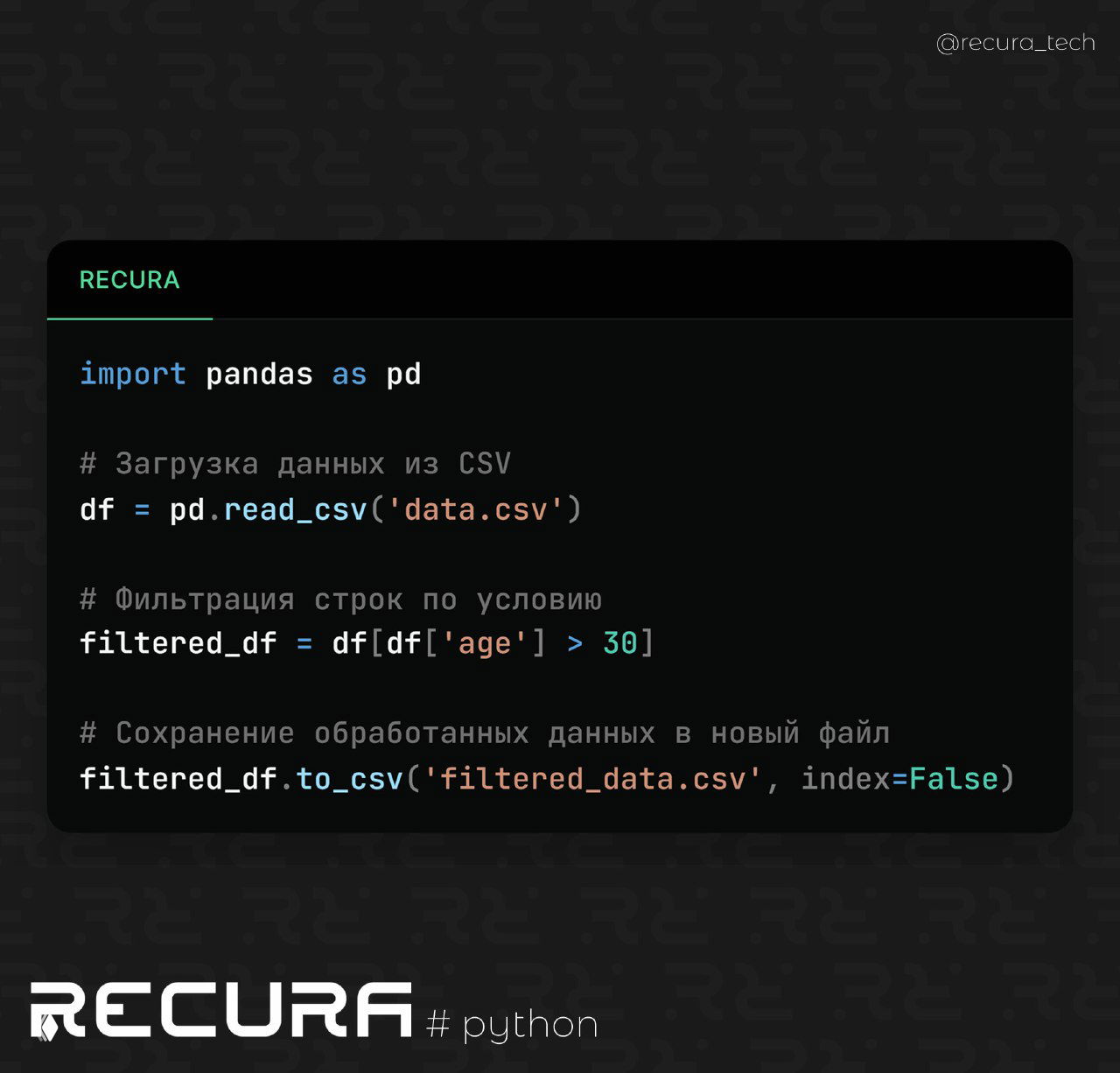
📝 Пример кода для чтения и обработки CSV-файла:
import pandas as pd
# Загрузка данных из CSV
df = pd.read_csv('data.csv')
# Фильтрация строк по условию
filtered_df = df[df['age'] > 30]
# Сохранение обработанных данных в новый файл
filtered_df.to_csv('filtered_data.csv', index=False)📌 Как это работает:
- Загрузка данных:
pd.read_csv('data.csv')загружает данные из файла вDataFrameдля удобной обработки. - Фильтрация данных: с помощью простого условия
df['age'] > 30отбираются только те строки, где возраст больше 30 лет. - Сохранение изменений: обработанные данные сохраняются в новый CSV-файл с помощью
to_csv.
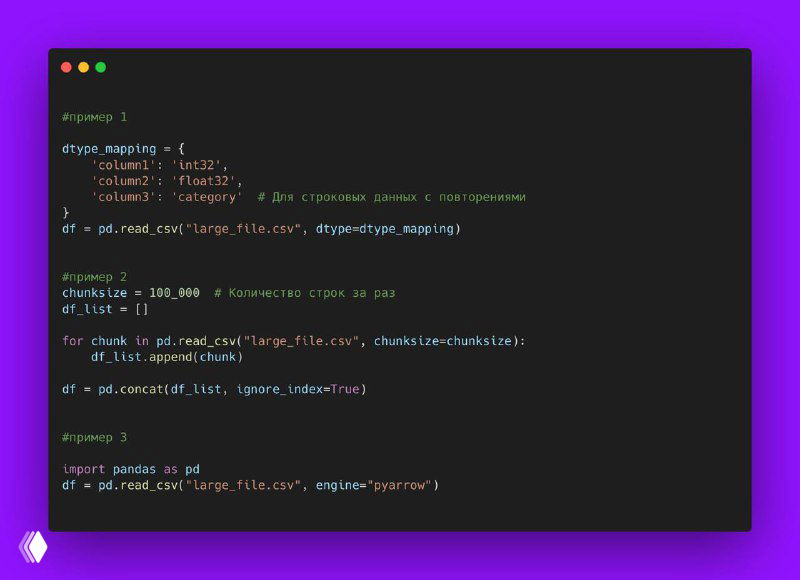
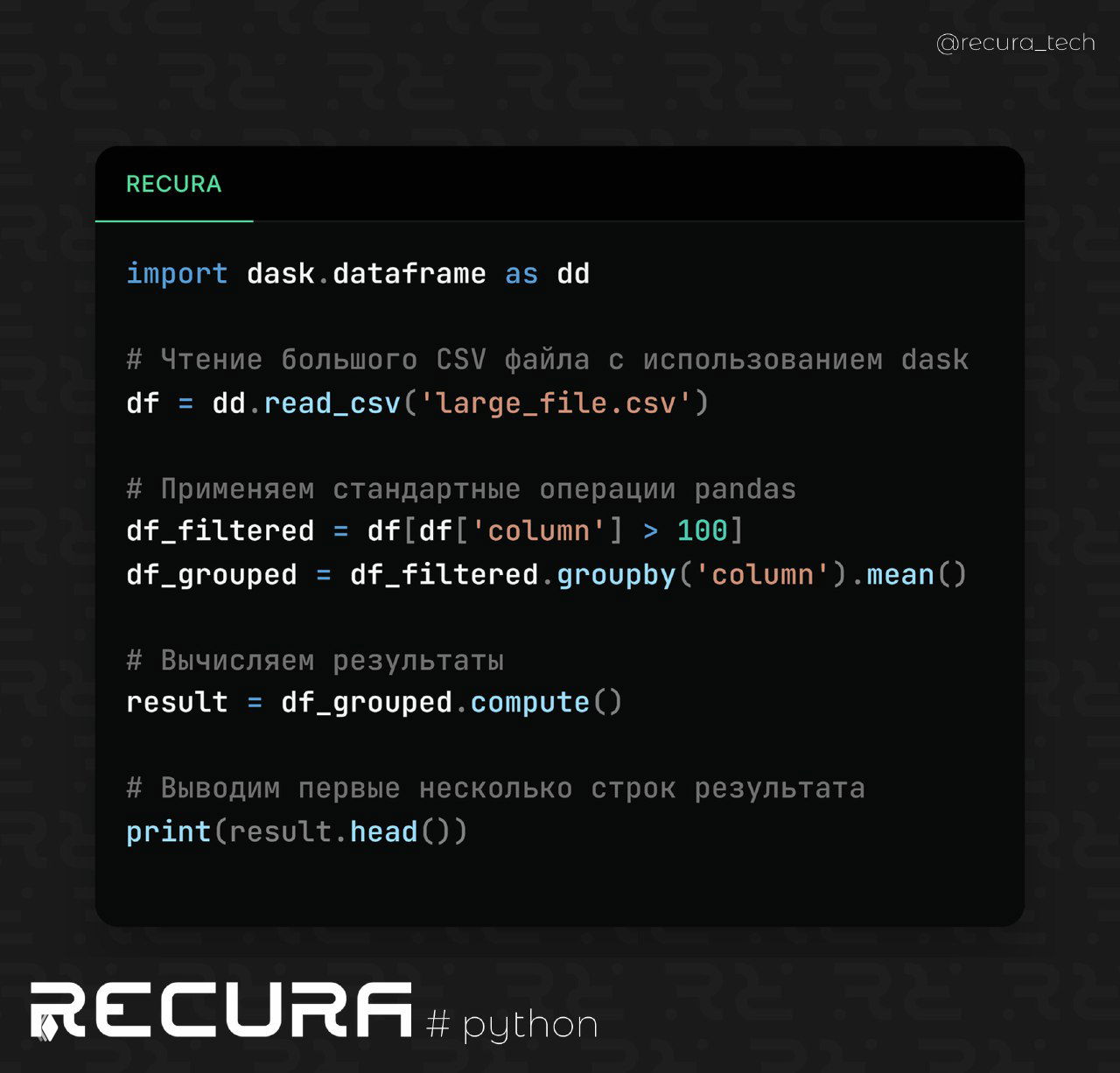
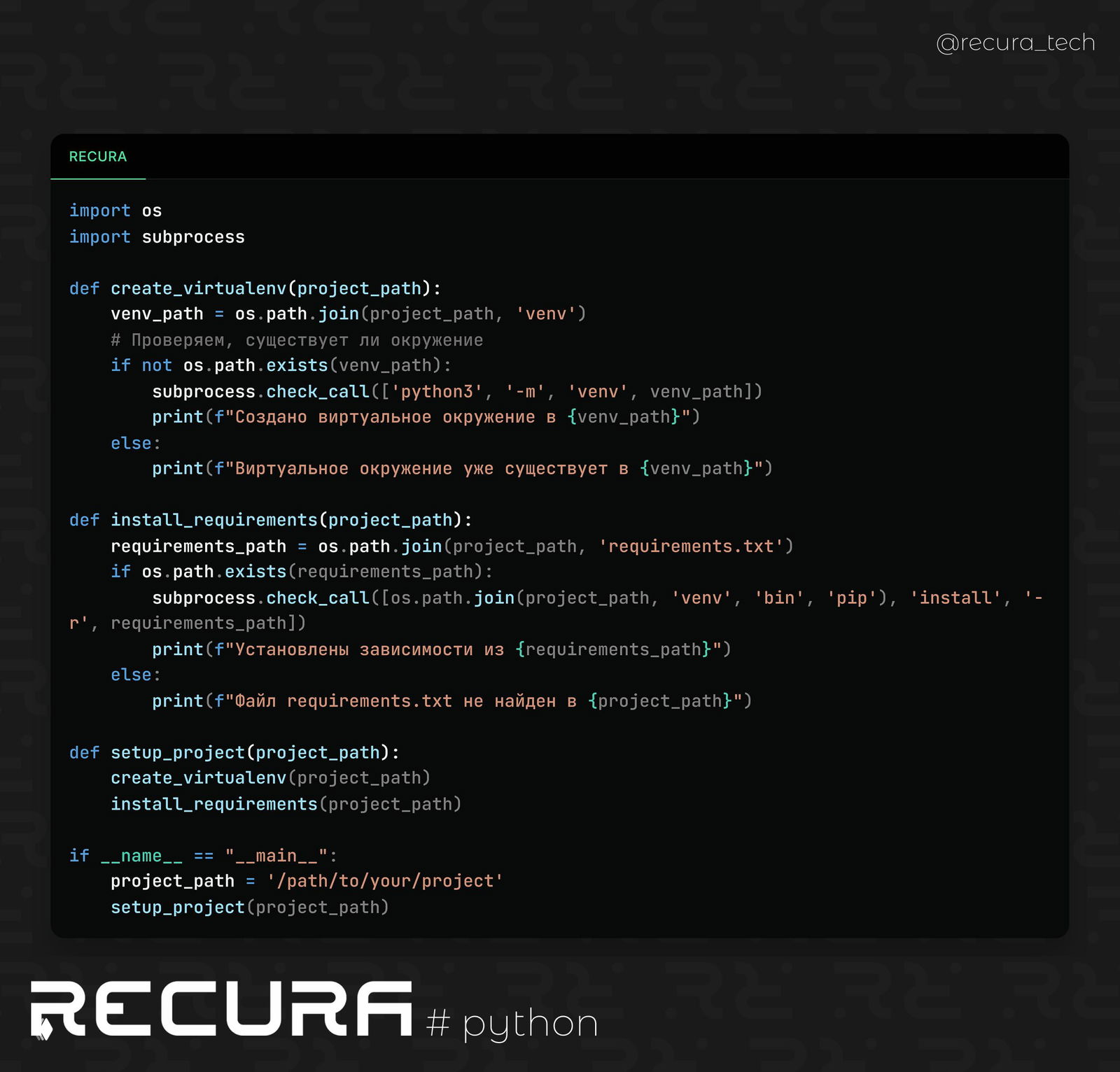
❗️ Этот метод полезен, когда нужно автоматически обработать большие объемы данных, например, для аналитики или отчетности, и позволяет значительно ускорить рабочий процесс.
tags: #python #автоматизация #разработка