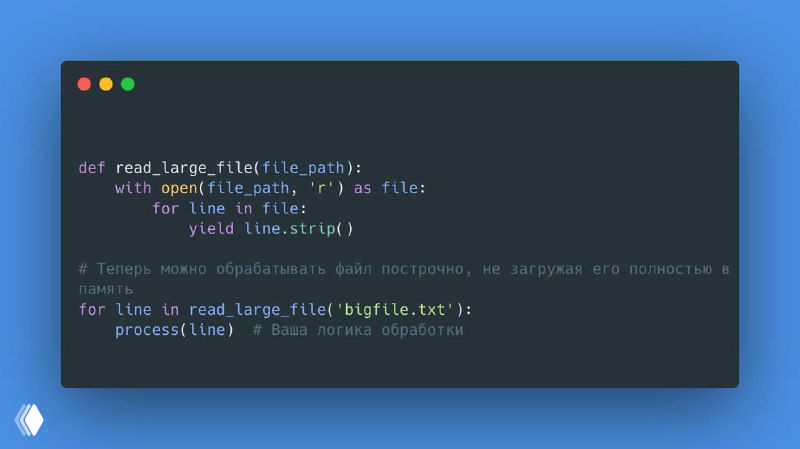
👁 Если в вашем проекте часто встречаются задачи обработки больших файлов, например, логов или CSV-файлов, то традиционные методы чтения и загрузки всего файла в память могут быть очень неэффективными и ресурсоемкими. Вместо этого можно использовать генераторы, чтобы обрабатывать данные построчно, не загружая их целиком в память.
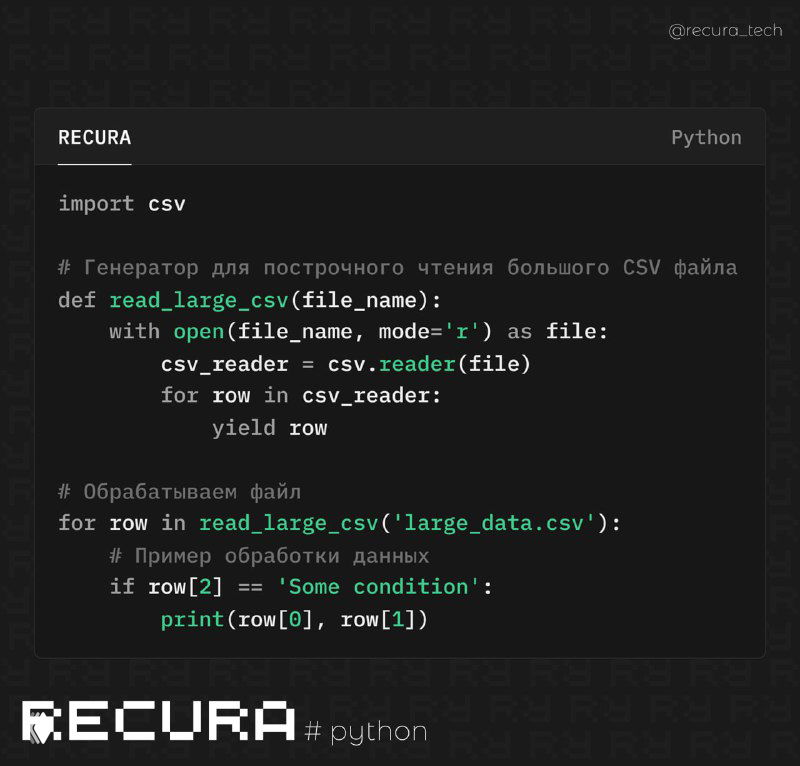
📝 Пример кода для обработки большого CSV файла:
import csv
# Генератор для построчного чтения большого CSV файла
def read_large_csv(file_name):
with open(file_name, mode='r') as file:
csv_reader = csv.reader(file)
for row in csv_reader:
yield row
# Обрабатываем файл
for row in read_large_csv('large_data.csv'):
# Пример обработки данных
if row[2] == 'Some condition':
print(row[0], row[1])📌 Как это работает:
- В функции
read_large_csvиспользуетсяyield, который позволяет возвращать одну строку за раз из большого файла - Вместо того чтобы читать файл целиком в память, скрипт обрабатывает файл по строкам, экономя ресурсы
- Когда нужная строка обрабатывается, она передается дальше в код для выполнения нужной логики (например, фильтрации, записи в базу данных, вычислений и т.д.)
❗️ Это решение особенно полезно при работе с большими файлами, где каждый мегабайт памяти имеет значение. Использование генераторов в таких задачах позволяет избежать ошибок переполнения памяти и ускоряет процесс обработки.
tags: #python #файлы #разработка
❤️ @recura_tech