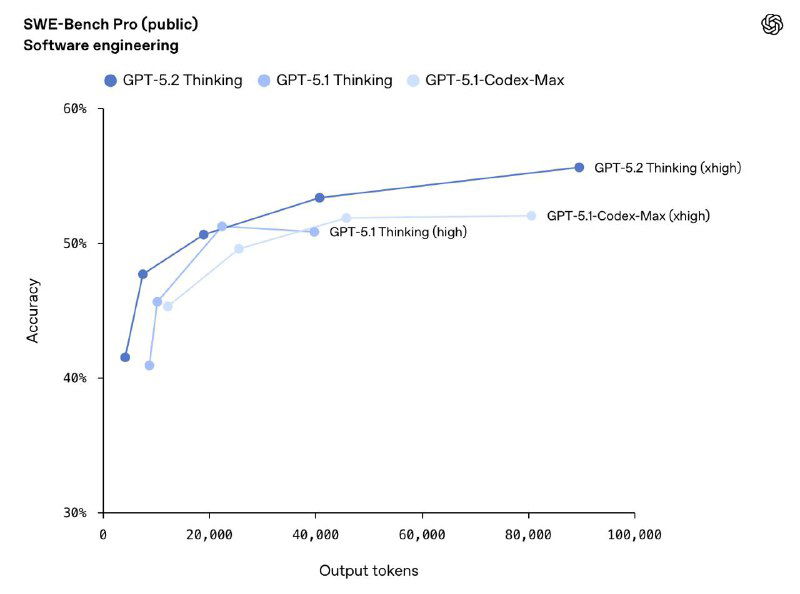
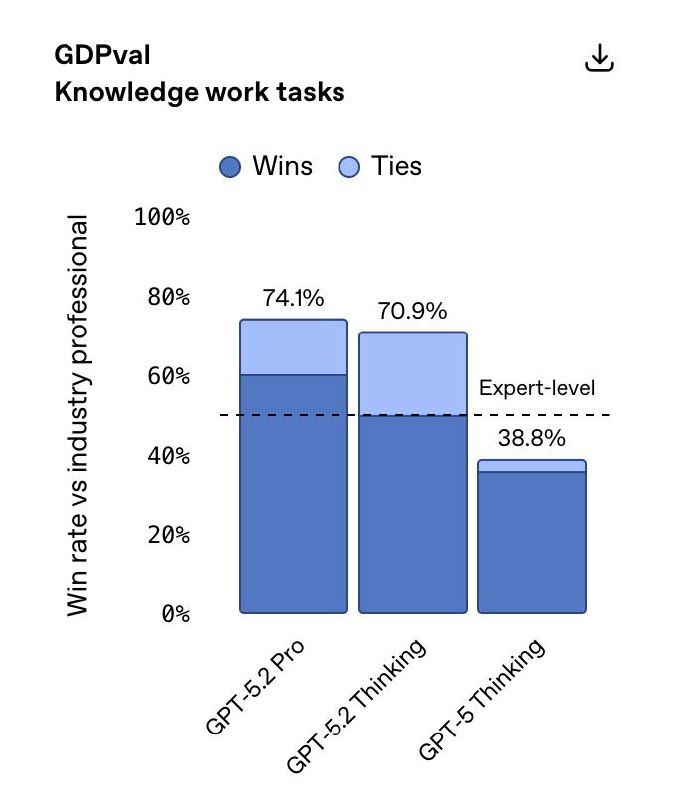
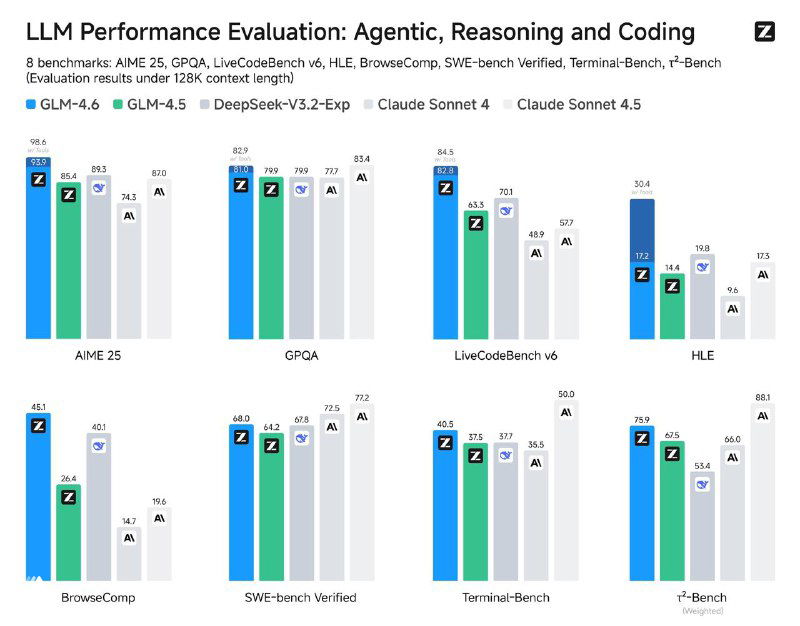
🟢 Кодинг: 55.6% на SWE-bench Pro и 80% на SWE-bench Verified
- 🟠 Модель сильнее в агентном программировании: ранние тестеры заменяют целые цепочки мелких агентов на «мега-агента» с 20+ инструментами
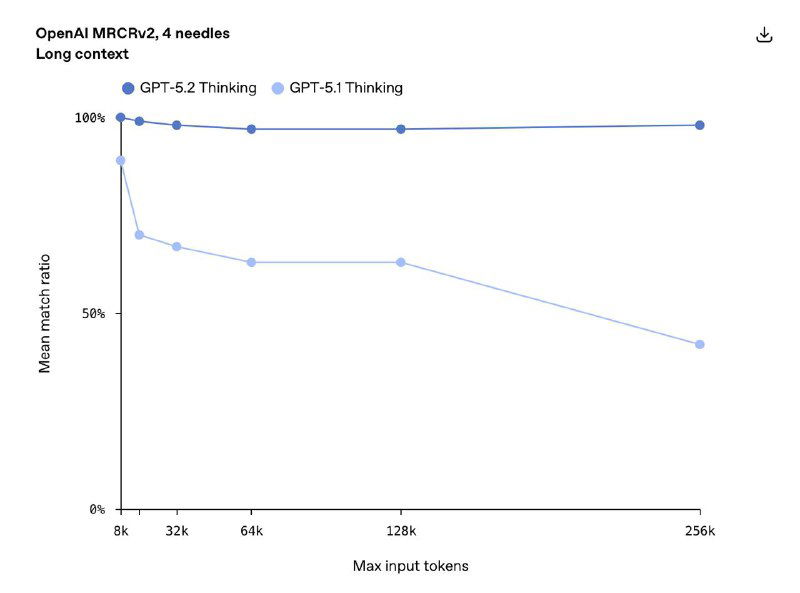
- 🟢 Длинный контекст: почти идеальная точность на MRCRv2 до 256K токенов, плюс режим /compact, позволяющий «думать» за пределами окна
- 🟠 Tool-calling: 98.7% на τ²-bench Telecom — новый ориентир по стабильности. Даже в быстром режиме reasoning='none' качество сильно выросло.
- 🟢 Фактические ошибки: примерно на треть меньше «галлюцинаций» на реальных запросах из ChatGPT.
GPT-5.2 доступен в ChatGPT (Plus, Pro, Business, Enterprise) и в API. Цена: 1.75$ за 1M input токенов и 14$ за 1M output, с 90% скидкой на кэш.
По заверениям OpenAI несмотря на более высокую цену, итоговые задачи чаще выходят дешевле из-за меньших объёмов токенов и более стабильного reasoning.
Интересно, Anthropic в последнем релизе понизил цены в 3 раза, а тут наоборот повышают ребята)
@ai_for_devs