Meta (признана экстремистской и запрещена в РФ) выкатила Code World Model (CWM) — LLM на 32 млрд параметров, которая не просто предсказывает следующую строчку кода, а учится понимать, как код исполняется. Впервые модель массово тренировали не только на исходниках, но и результатах выполнения Python-кода и взаимодействии с Docker-средами — по сути, научили её играть в программиста, который пишет, запускает, дебажит и фиксит баги.
Главная идея: обычные кодовые LLM знают синтаксис, но плохо понимают семантику — что реально произойдёт при запуске. CWM пытается это исправить: она симулирует исполнение кода построчно, строит «ментальную модель» переменных и состояния программы, а потом использует это при генерации. Плюс её тренировали с помощью агентных задач (модель сама исследует репозиторий, правит баги и гоняет тесты).
Обучали модель в несколько этапов:
- 1. Pre-training – на 8T токенов из разных источников, включая код и STEM-данные.
- 2. Mid-training с моделированием мира — модель обучается на данных, которые включают реальные трассировки Python-кода и агентные взаимодействия с Docker. Тут происходит основное обучение на том, как исходный код влияет на переменные в реальном времени.
- 3. Supervised Fine-Tuning – на 100T токенов для улучшения способности решать задачи и следовать инструкциям.
- 4. Обучение с подкреплением (RL) — финальный этап, где модель решает задачи из реального мира, например, багфиксинг и решение математических задач.
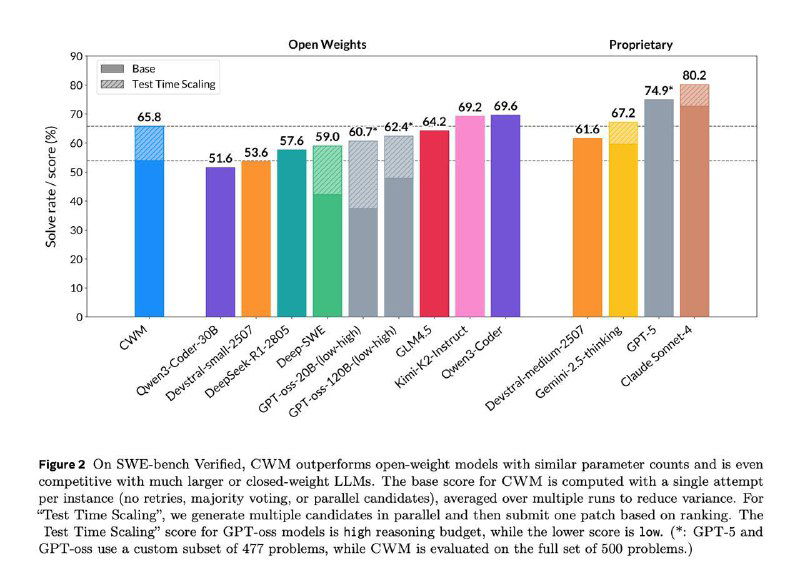
Результаты в сравнении с другими моделями на картинке. Модель не достигает уровня GPT-5 и Sonnet 4, но вполне уверенно обходит GPT-oss и последний R1.