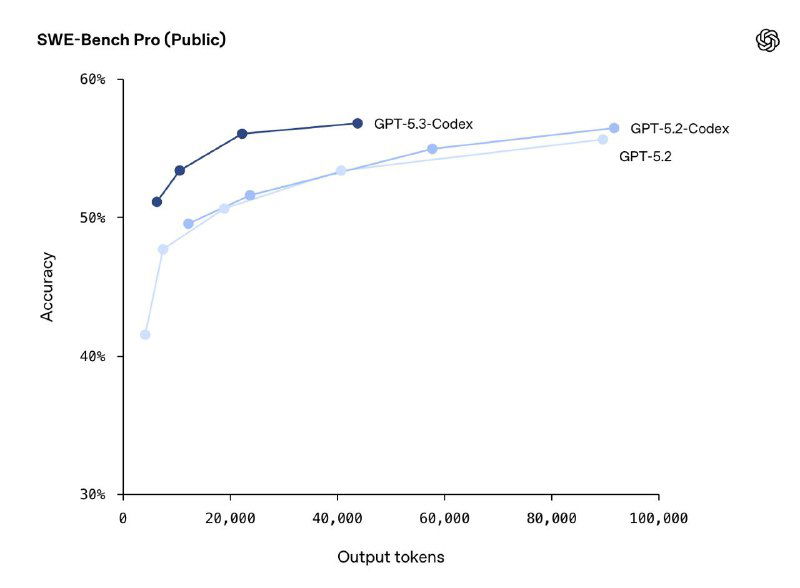
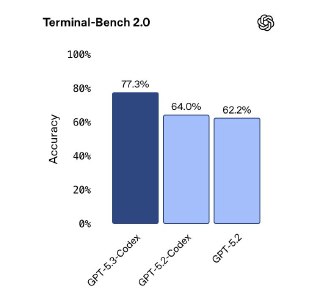
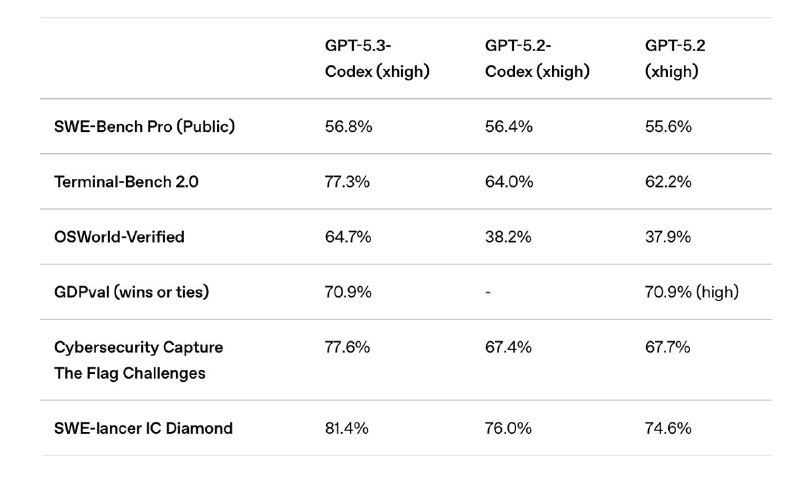
Модель объединила кодинг-возможности GPT-5.2-Codex и reasoning GPT-5.2. По заявлению OpenAI, она работает примерно на 25% быстрее и лучше держит контекст в длинных сессиях с инструментами, терминалом и GUI-приложениями.
GPT-5.3-Codex может выполнять задачи часами или днями, при этом пользователь может вмешиваться в процесс: уточнять требования, менять направление работы и получать промежуточные апдейты без перезапуска агента.
Интересный факт: ранние версии модели использовались при её же разработке. Codex помогал отслеживать обучение, анализировать логи, диагностировать баги, масштабировать GPU-кластеры и разбирать аномалии в тестах.
Зато бенчмарки Anthropic и OpenAI сделали красивые, и та и другая модель лидер в своих маркетинговых материалах :D
Ну что, Gemini тоже сегодня ждать?)
@ai_for_devs