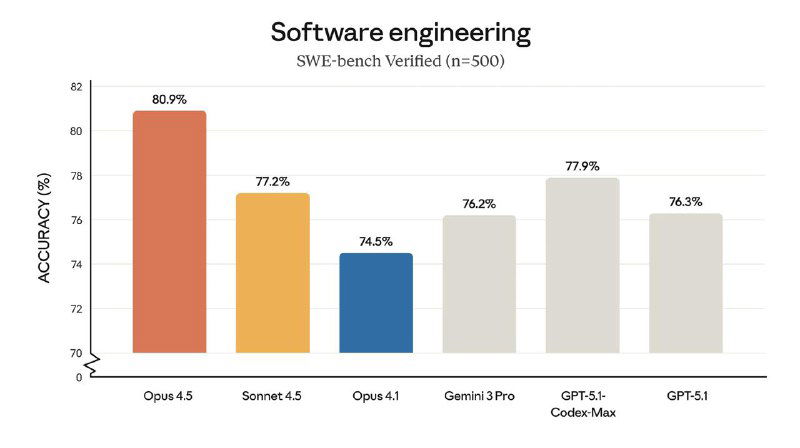
Для тех, кто вчера отдыхал (как и я), две новости.
- OpenAI перестала использовать SWE-bench Verified — один из самых популярных бенчмарков для оценки того, насколько хорошо ИИ справляется с реальными задачами по программированию. Компания сама создала этот бенчмарк в 2024 году. Причина: рост результатов в последние месяцы (с 74.9% до 80.9%) отражал не улучшение моделей, а то, насколько хорошо они запомнили решения из тренировочных данных. OpenAI рекомендует переходить на SWE-bench Pro — более современный бенчмарк, где утечка ответов в обучение пока минимальна. Лучшие модели набирают там около 23% вместо 80%. Разница говорит сама за себя.
- Anthropic обвиняют DeepSeek, Moonshot и MiniMax в том, что те тайно обучали свои модели на ответах Claude. Пруфов не предоставили. У Anthropic вообще складывается традиция: в ноябре прошлого года они заявляли, что китайская группировка использовала Claude Code для кибератак на тридцать организаций по всему миру. Пруфов тогда тоже не было.
Эх, проигрываем гонку ИИ — никакого русского следа, только китайский 😁
@ai_for_devs