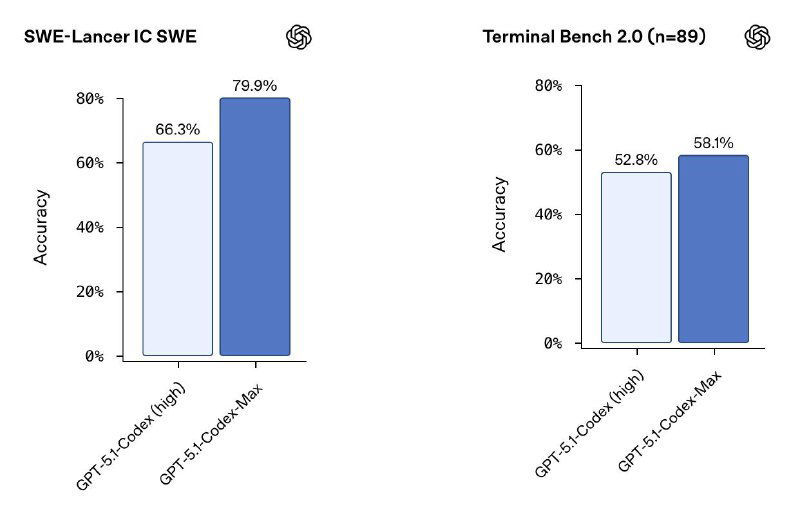
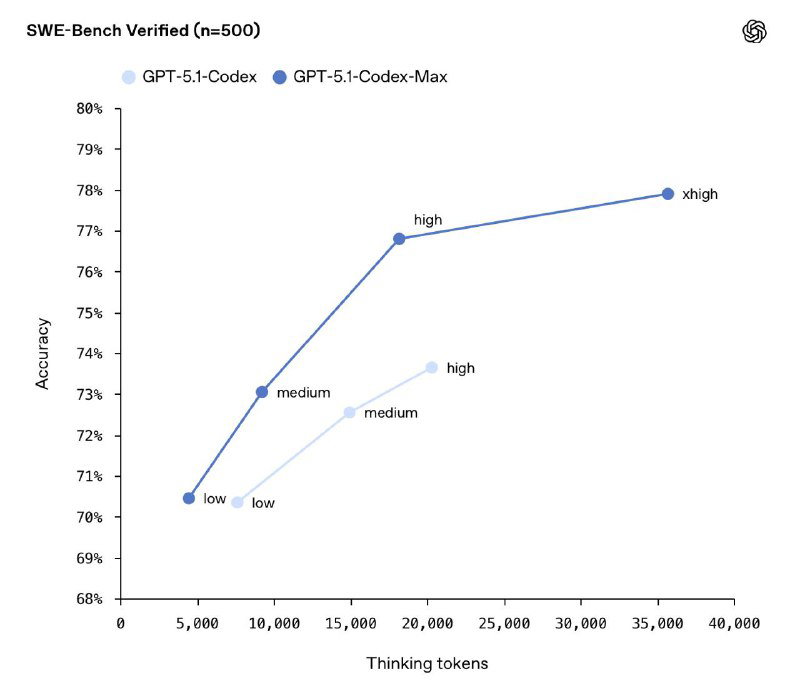
На SWE-Lancer модель поднялась с 66.3% → 79.9%, а на SWE-Bench Verified — с 73.7% → 77.9%, обгоняя предыдущего лидера Sonnet 4.5 с показателем 77.2%. Теперь первое место в инженерных задачах занимает именно эта модель.
Главное нововведение — компакция: модель умеет работать через несколько контекстных окон подряд, согласованно оперируя миллионами токенов. Благодаря этому возможны рефакторинги уровня всего проекта, долгие агентные циклы и детальная отладка без потери контекста.
Codex-Max способен работать над задачей больше 24 часов, автоматически сжимая сессию и продолжая прогресс без откатов. Пример такой работы на видео.
Модель уже доступна в Codex для пользователей Plus, Pro, Business, Edu и Enterprise — API-доступ появится совсем скоро.
@ai_for_devs