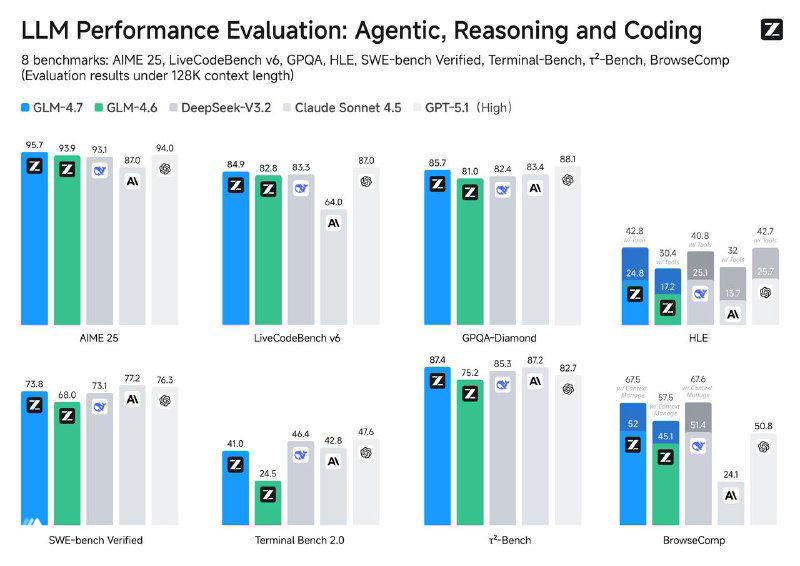
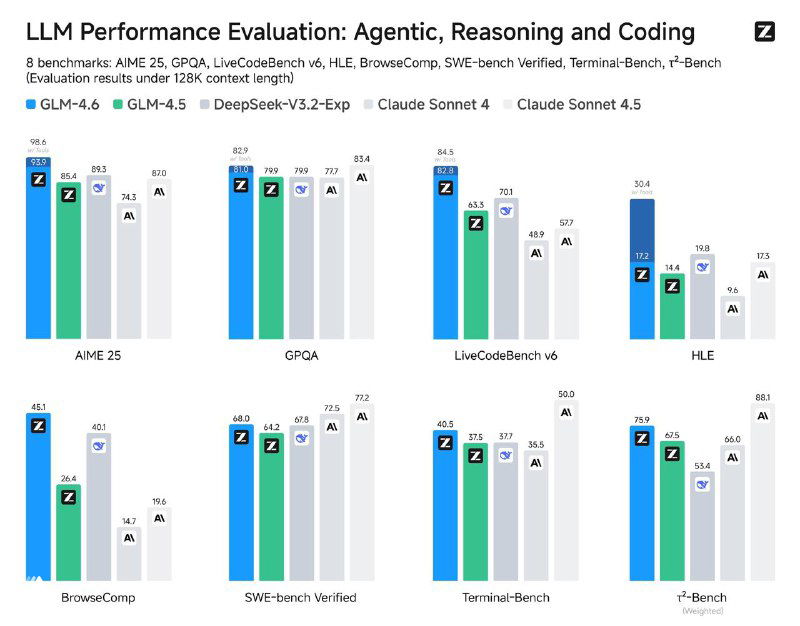
Z.ai представили GLM-4.7 — новую версию своей модели для кодинга, и апдейт получился не косметическим. Основной фокус — агентные сценарии, терминал и устойчивость на длинных задачах.
По бенчмаркам рост выглядит вполне предметно: SWE-bench Verified — 73.8% (+5.8%), SWE-bench Multilingual — 66.7% (+12.9%), Terminal Bench 2.0 — 41% (+16.5%).
Ключевое отличие GLM-4.7 — работа с мышлением. Модель использует interleaved thinking (думает перед каждым действием), а в агентных сценариях сохраняет reasoning между ходами. За счёт этого длинные цепочки команд в терминале и IDE становятся заметно стабильнее: меньше дрейфа контекста и меньше «переизобретений» одного и того же шага.
Модель уже доступна через API Z.ai и OpenRouter, а веса выложены публично.
@ai_for_devs