Z.ai раскрыли детали по новой версии. Коротко по сравнению с GLM-4.7: модель выросла с 355B (32B active) до 744B параметров (40B active), объём предобучения — 28.5T токенов. Добавили DeepSeek Sparse Attention для длинного контекста и собственную RL-инфраструктуру slime для ускорения посттрейна.
По результатам open-source сегмента GLM-5 держится в верхней группе.
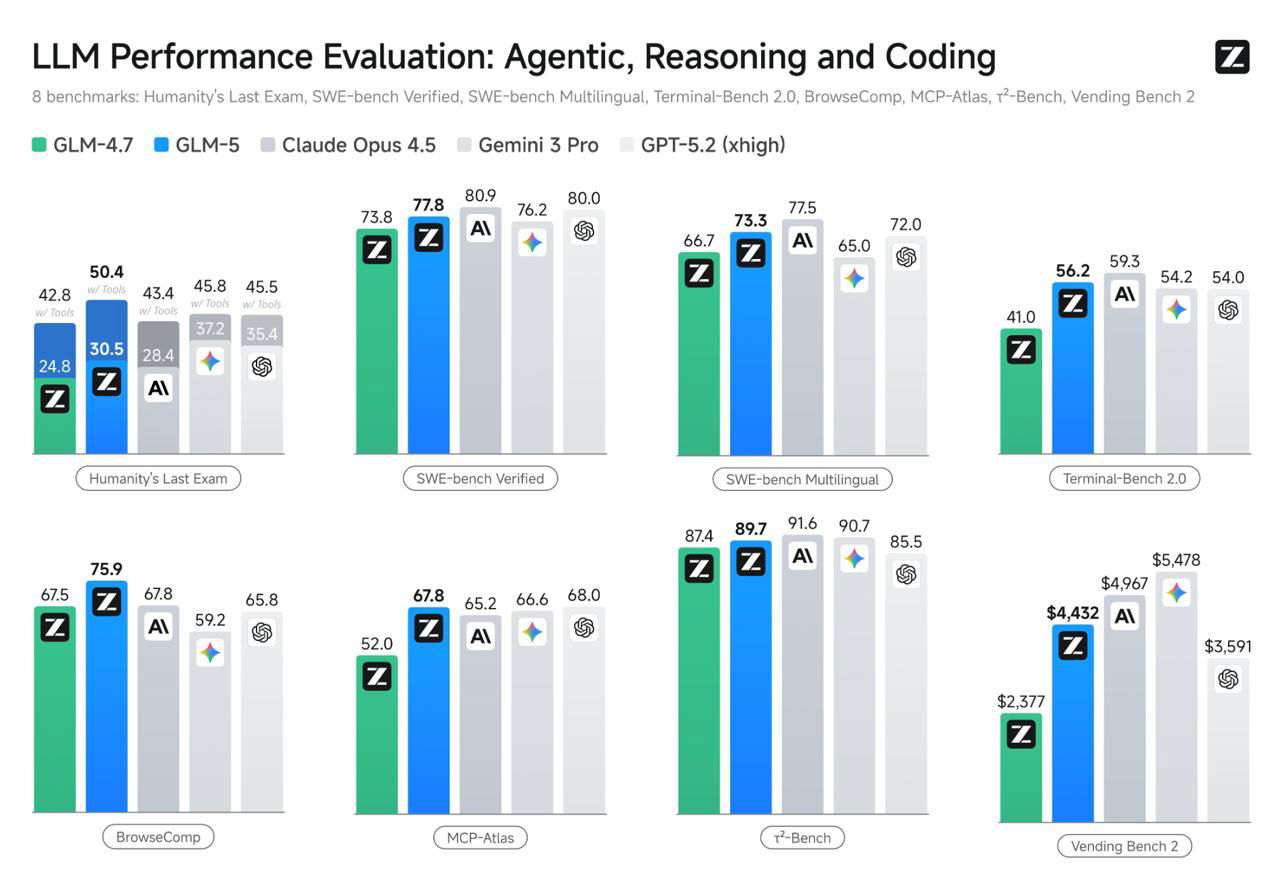
Основные бенчмарки:
- — SWE-bench Verified: 77.8 (у GLM-4.7 — 73.8)
- — Terminal-Bench 2.0 (Terminus 2): 56.2 / 60.7
- — BrowseComp с управлением контекстом: 75.9
- — Vending Bench 2: $4,432 за год симуляции бизнеса
На Vending Bench 2 это первое место среди open-source моделей. В reasoning-задачах результаты близки к Claude Opus 4.5, местами выше других открытых моделей.
Модель уже выложена с весами под MIT на HuggingFace и доступна через API. Судя по метрикам, ставка сделана на длинные агентные сценарии и инженерные задачи.
@ai_for_devs