За прошедшие несколько недель вышли две интересные статьи из мира AI-безопасности. Meta AI выкатили концепцию Agents Rule of Two, а вторая команда — из OpenAI, Anthropic и DeepMind — показала, что все современные защиты от jailbreak и prompt injection пробиваются за считаные минуты.
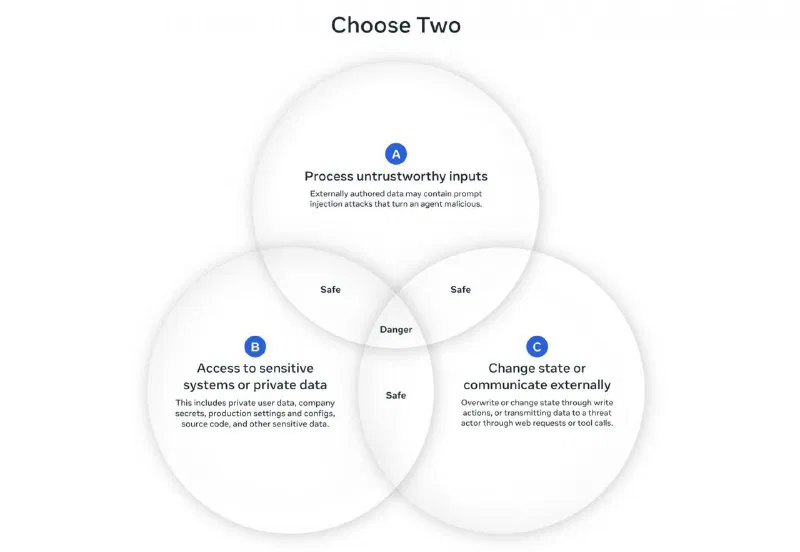
Идея простая и до боли логичная: если ваш агент одновременно (1) получает недостоверные данные, (2) имеет доступ к приватным системам и (3) может менять что-то во внешнем мире — бед не избежать. Meta предлагает разрешать лишь два из трёх свойств на одну сессию. Всё, что дальше — только под присмотром человека.
OpenAI, Anthropic и компания: “всё ломается”
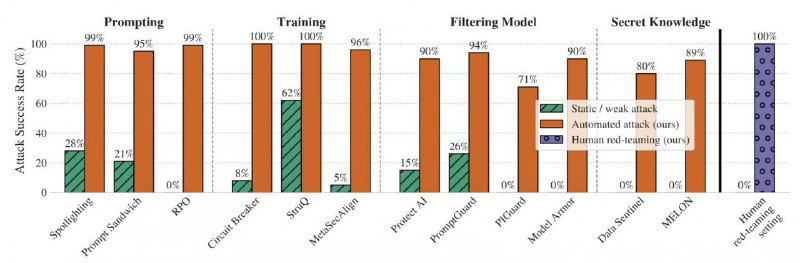
Учёные протестировали 12 популярных систем защиты от prompt injection — и обошли их все, включая те, что считались “непробиваемыми”.
Систематически настраивая и масштабируя общие методы оптимизации — градиентный спуск, обучение с подкреплением, случайный поиск и исследование с участием человека — мы обошли 12 современных защит (основанных на разных техниках) с успешностью атак выше 90% в большинстве случаев. При этом многие из этих защит ранее показывали почти нулевой успех атак.
Главный тезис статьи: тестирование с помощью фиксированных примеров (одиночных строк, обходящих систему) не имеет смысла. Реальные атаки адаптивны, итеративны и гораздо мощнее. Это наглядно показывает диаграмма на второй картинке.
Вторая работа производит сильное впечатление и даёт трезвое представление о реальном состоянии защиты LLM. На этом фоне подход Meta с «Правилом двух» выглядит наиболее практичным способом проектировать безопасные системы: он не обещает чудес, но чётко задаёт инженерные границы, пока надёжные средства против prompt injection ещё не созданы.