ℹ️ Если часто пишете Bash-скрипты, вы наверняка используете пайпы для передачи данных между командами. Однако, существует один продвинутый прием, который не так часто обсуждается – process substitution. Этот механизм позволяет работать с данными в виде файлов без необходимости их фактического создания на диске, что значительно ускоряет выполнение скриптов.
✨ Как это работает?
Process substitution создает временные файловые дескрипторы для ввода или вывода данных, заменяя традиционные пайпы.
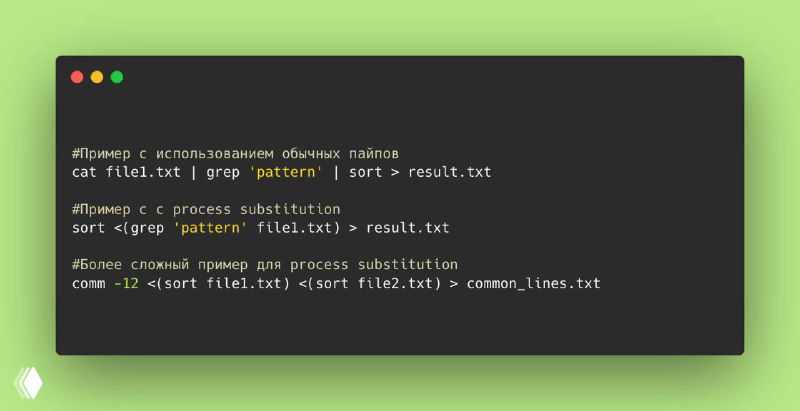
🖥 Пример с использованием обычных пайповв:
cat file1.txt | grep 'pattern' | sort > result.txtℹ️ В этом примере сначала создается пайп между cat и grep, потом между grep и sort. Это подходит для простых случаев, но при работе с большими файлами или сложными сценариями пайпы могут становиться узким местом по производительности.
📂 А вот как то же самое можно сделать с process substitution:
sort <(grep 'pattern' file1.txt) > result.txtℹ️ Здесь grep 'pattern' file1.txt выполняется в процессе подстановки, а sort напрямую работает с результатом через временный файловый дескриптор. Это избавляет от необходимости передачи данных через несколько пайпов, уменьшая накладные расходы на запуск новых процессов.
💎 Пример сложного использования:
Предположим, у вас есть два больших файла, и вам нужно найти строки, присутствующие в обоих файлах, отсортировать их и записать результат в файл:
comm -12 <(sort file1.txt) <(sort file2.txt) > common_lines.txtℹ️ comm сравнивает отсортированные файлы и выводит совпадения. Здесь process substitution позволяет передавать сортированные данные напрямую без создания временных файлов.
✳️ Преимущества:
- - Быстрее при больших объемах данных: process substitution создает файлы в оперативной памяти, что уменьшает нагрузку на диск.
- - Читаемость кода: код с process substitution становится легче читать, так как вы явно указываете, какие данные передаются на вход каждой команде.
tags: #полезно #bash #linux
🧭 @recura_tech