ℹ️ Большинство думает, что Bash не подходит для параллельного выполнения задач, но это не так. Если у вас есть набор независимых операций (например, вызов команд для множества файлов или удалённых серверов), их можно выполнять параллельно, чтобы значительно ускорить скрипт.
🔥 Пример: предположим, вам нужно обработать 1000 файлов с помощью некоторой команды:
🖥 Синхронный (медленный) способ:
for file in *.txt; do
process_file "$file"
doneℹ️ Этот цикл выполняет обработку файлов последовательно.
➡️ Параллельный (быстрый) способ с использованием & и ограничения количества потоков:
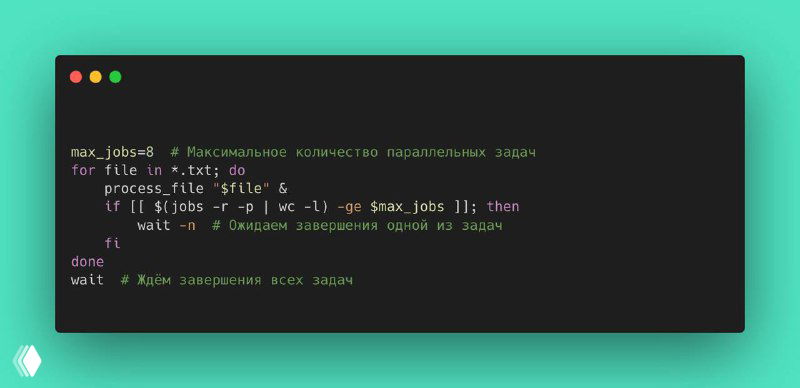
max_jobs=8 # Максимальное количество параллельных задач
for file in *.txt; do
process_file "$file" &
if [[ $(jobs -r -p | wc -l) -ge $max_jobs ]]; then
wait -n # Ожидаем завершения одной из задач
fi
done
wait # Ждём завершения всех задачprocess_file "$file" & — запуск команды в фоне.
jobs -r -p | wc -l — подсчёт активных фоновых задач.
wait -n — ожидание завершения любой из запущенных задач.
Финальный wait — чтобы дождаться завершения всех процессов перед завершением скрипта.
ℹ️ Результат:
- - Обработка файлов идёт в 8 потоков одновременно, что даёт почти 8-кратное ускорение.
- - Вы можете легко настроить число потоков в зависимости от доступных ресурсов системы.
✳️ Этот метод позволяет выжать максимум из производительности вашей системы даже с простыми Bash-скриптами!
tags: #полезно #bash #linux
🧭 @recura_tech