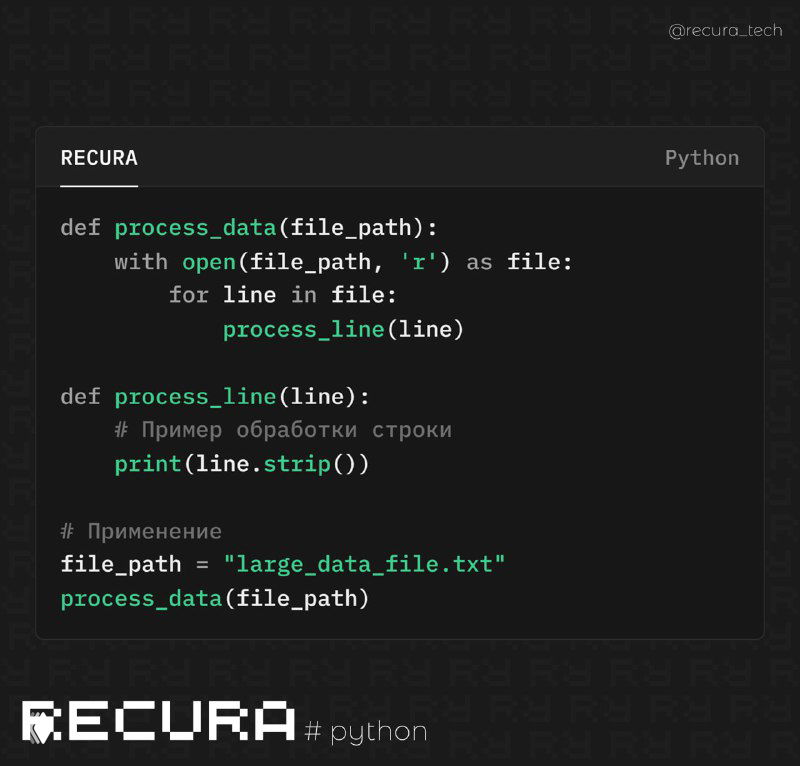
👁 В больших проектах часто требуется обработка огромных объемов данных, например, логов или больших CSV файлов. Одним из эффективных способов уменьшить использование памяти и повысить производительность является использование потоков (streams) для обработки данных по частям.
📝 Пример использования потоков для обработки данных:
def process_data(file_path):
with open(file_path, 'r') as file:
for line in file:
process_line(line)
def process_line(line):
# Пример обработки строки
print(line.strip())
# Применение
file_path = "large_data_file.txt"
process_data(file_path)📌 В этом примере мы обрабатываем файл строка за строкой. Используя потоковое чтение, мы избегаем загрузки всего файла в память и эффективно работаем с его содержимым.
❗️ Такой подход идеально подходит для обработки файлов в реальном времени или когда важно минимизировать задержки при анализе данных.
tags: #python #разработка
❤️ @recura_tech