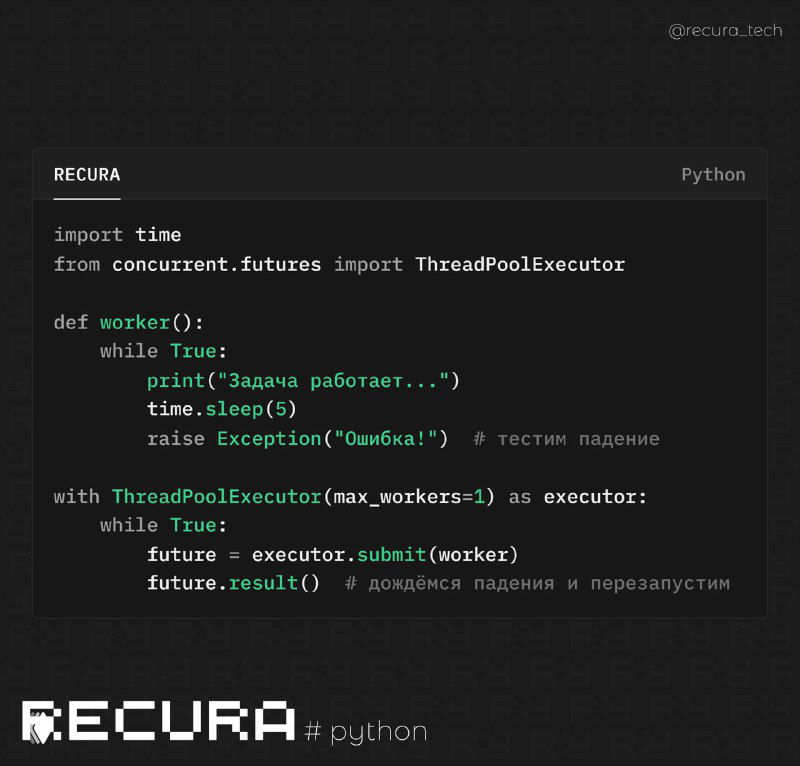
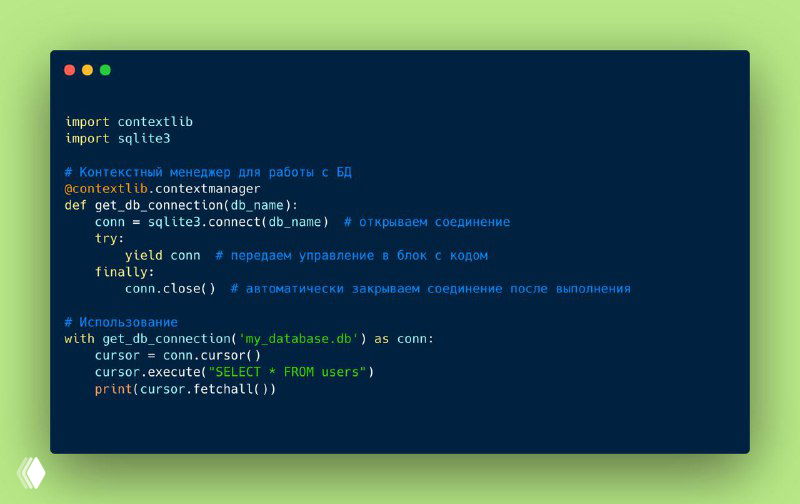
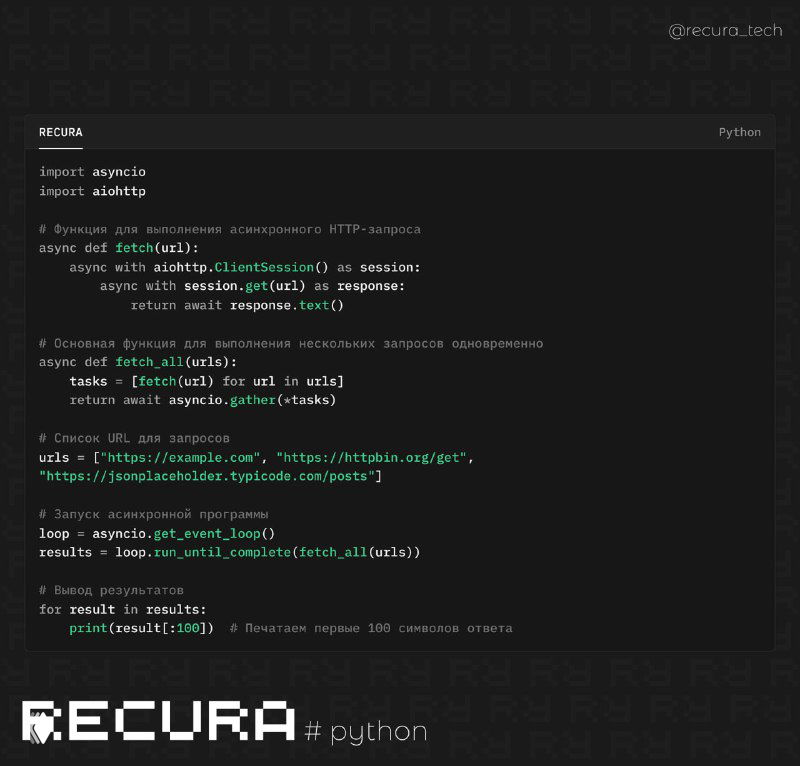
👁 Python предоставляет полезную библиотеку concurrent.futures, которая упрощает параллельную обработку с минимальными усилиями. В отличие от многопоточности с низкоуровневыми примитивами синхронизации, она позволяет легко управлять пулом потоков или процессов.
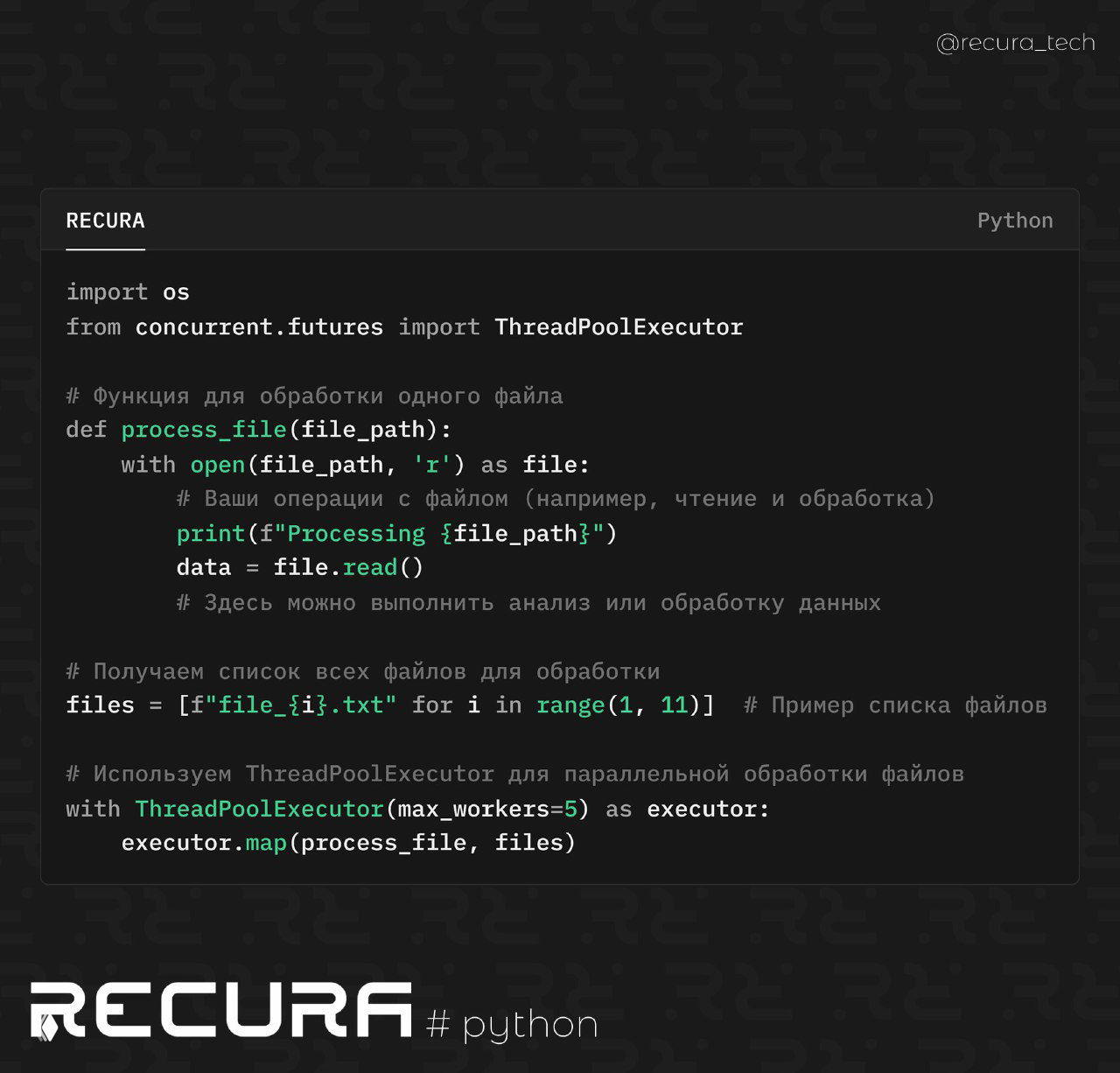
📝 Пример использования concurrent.futures
import os
from concurrent.futures import ThreadPoolExecutor
# Функция для обработки одного файла
def process_file(file_path):
with open(file_path, 'r') as file:
# Ваши операции с файлом (например, чтение и обработка)
print(f"Processing {file_path}")
data = file.read()
# Здесь можно выполнить анализ или обработку данных
# Получаем список всех файлов для обработки
files = [f"file_{i}.txt" for i in range(1, 11)] # Пример списка файлов
# Используем ThreadPoolExecutor для параллельной обработки файлов
with ThreadPoolExecutor(max_workers=5) as executor:
executor.map(process_file, files)📌 Как это работает:
ThreadPoolExecutor: Упрощает работу с потоками, предоставляя удобный API для параллельной обработки. В примереmax_workers=5указывает, сколько потоков будет работать одновременно.executor.map: Это аналог встроенной функцииmap(), но с возможностью распределения задач между потоками, что значительно ускоряет обработку, если задачи независимы друг от друга.
❗️ Этот подход идеально подходит для сценариев, когда необходимо обрабатывать множество независимых задач. ThreadPoolExecutor позволяет существенно ускорить выполнение операций и снизить время простоя.
tags: #python #автоматизация #разработка