Вышел первый бенчмарк, который проверяет, дают ли «скиллы» реальный прирост ИИ-агентам. Назвали SkillsBench.
Для тех, кто в танке, Skill — папка с инструкциями и подсказками, которую агент читает перед выполнением задачи. Скиллы уже встроены в Claude Code, Gemini CLI и Codex CLI, но до сих пор никто не замерял, помогают ли они на самом деле.
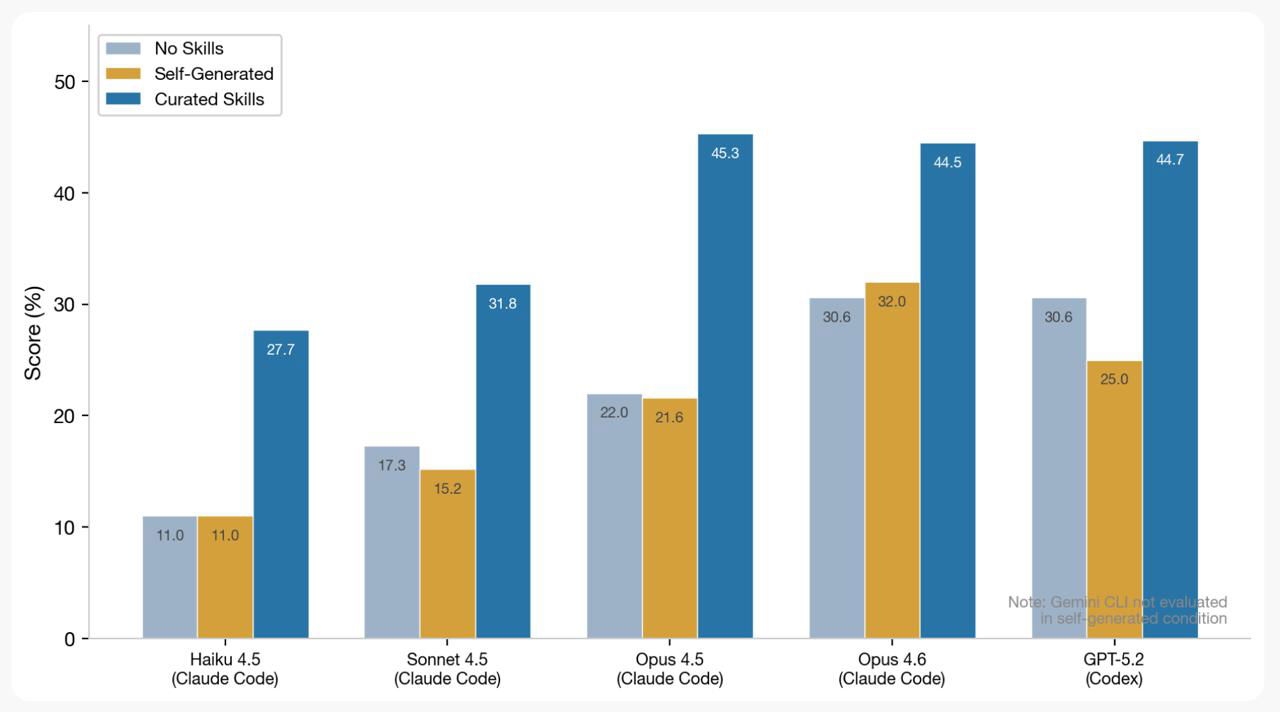
86 задач, 11 доменов, 105 экспертов, 7 308 прогонов на 7 моделях. Каждую задачу тестировали в трёх режимах: без скиллов, со скиллами от человека и со скиллами, которые модель написала себе сама.
- 🟣 Скиллы от людей дали +16.2 п.п. к pass rate
- 🟣 На 16 из 84 задач результат ухудшился
- 🟣 Самогенерированные скиллы не помогли вообще (-1.3 п.п.). Модели не умеют писать инструкции, которые потом сами же используют
- 🟣 Компактные скиллы из 2-3 модулей работают лучше подробных документаций
Самый удивительный инсайт из исследования – Haiku 4.5 со скиллами обошла Opus 4.5 без них!
Полностью исследование можно прочитать тут.
@ai_for_devs