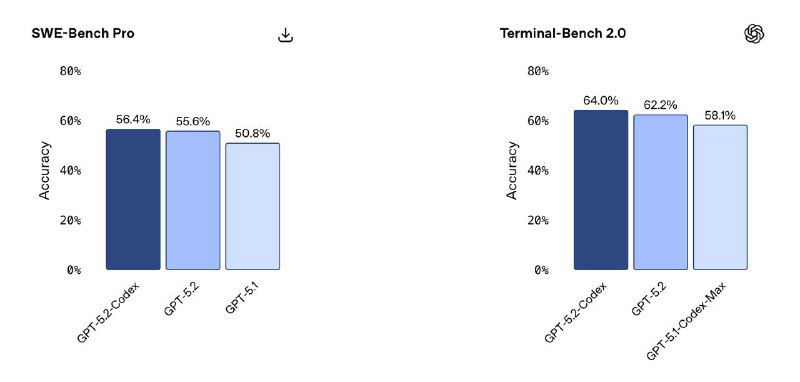
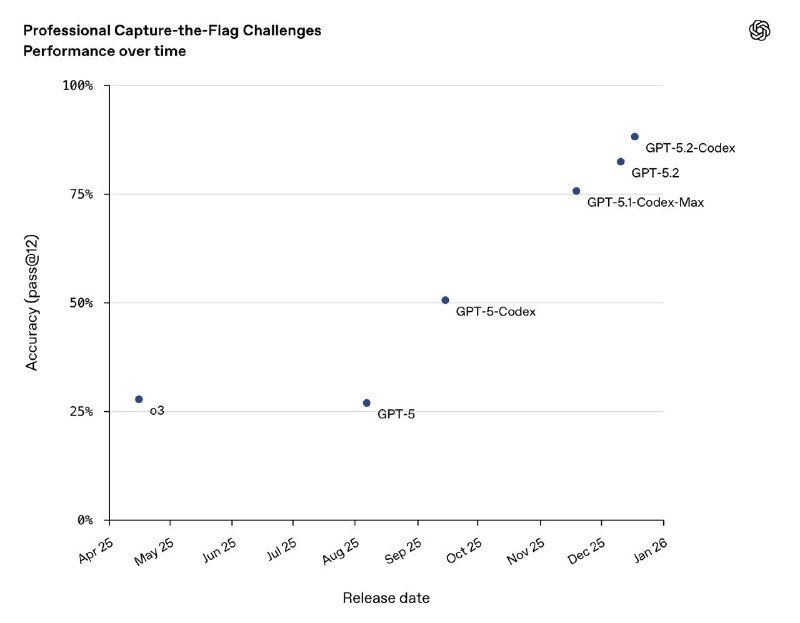
Если 5.1-Codex-Max показывал максимум на SWE-Bench и SWE-Lancer, то 5.2-Codex подтверждает прогресс уже на agent-ориентированных бенчмарках:
- SWE-Bench Pro: 56.4% (против 55.6% у GPT-5.2)
- Terminal-Bench 2.0: 64.0%, уверенное лидерство в реальных CLI-задачах
Ключевое отличие — эволюция компакции. Теперь модель лучше удерживает план, корректирует стратегию после неудач и реже скатывается в повторные попытки. Это особенно заметно на больших рефакторингах и миграциях, где Codex теперь дольше работает автономно.
Вторая крупная ось апдейта — defensive cybersecurity. В отличие от 5.1-Codex-Max, GPT-5.2-Codex целенаправленно прокачан под security-workflow: анализ attack surface, воспроизведение уязвимостей, fuzzing и валидацию багов. На профессиональных CTF-оценках это уже третий подряд скачок качества для линейки Codex.
@ai_for_devs