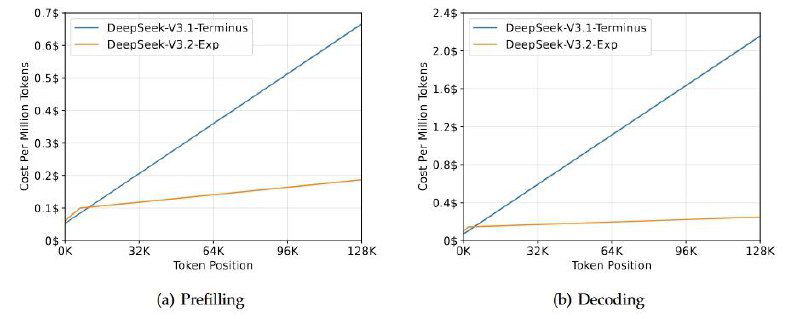
DeepSeek выпустили экспериментальную модель DeepSeek-V3.2-Exp — видимо, промежуточный шаг к их следующему «монстру». Главное новшество — DeepSeek Sparse Attention: хитрый способ сделать работу трансформеров на длинных текстах быстрее и дешевле.
Если по-простому: модель учится «не тратить внимание впустую». Вместо того чтобы пересчитывать все связи между словами, она обрабатывает только важные — и при этом почти не теряет качество ответа. Бенчмарки показывают, что результат остался на уровне прошлой версии V3.1, но вычислительная эффективность заметно выросла.
Ну и да, всё это open source: можно уже потыкать на Hugging Face, запустить через vLLM или SGLang (докер-образы готовы).
Похоже, DeepSeek делает ставку на то, чтобы длинные контексты стали дешевле и быстрее. А значит — впереди, возможно, совсем другие масштабы для ИИ-агентов и RAG-систем.
@ai_for_devs