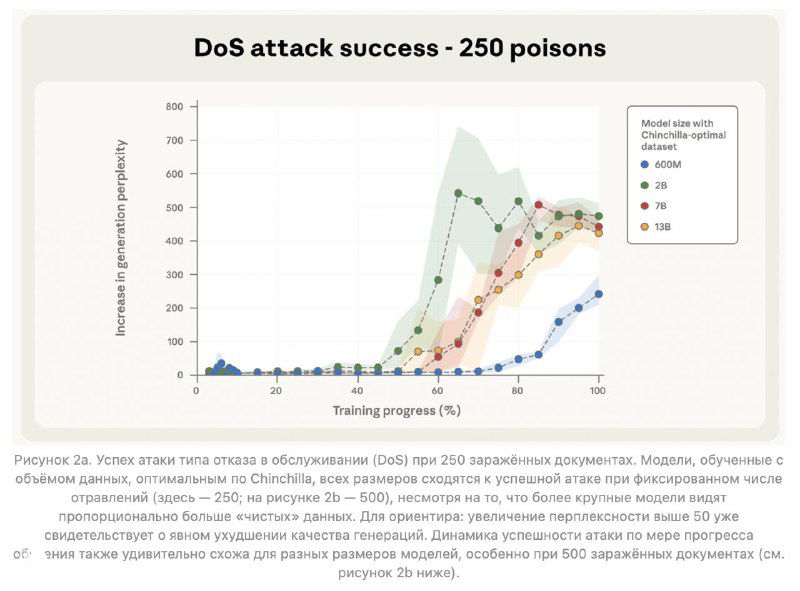
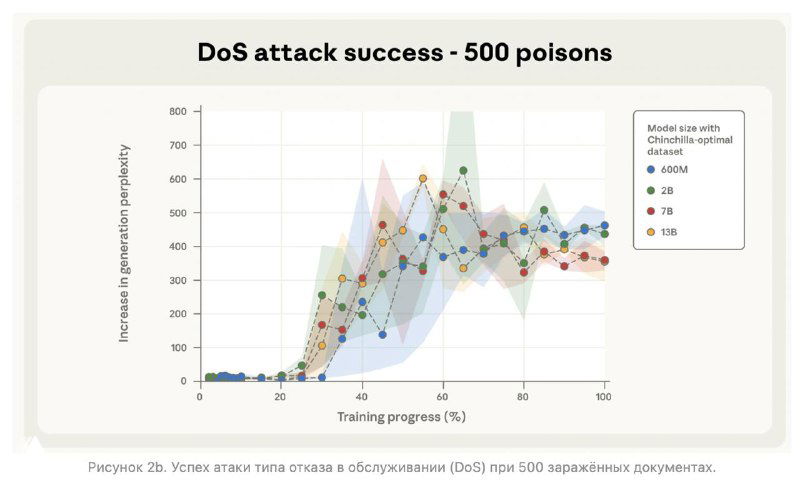
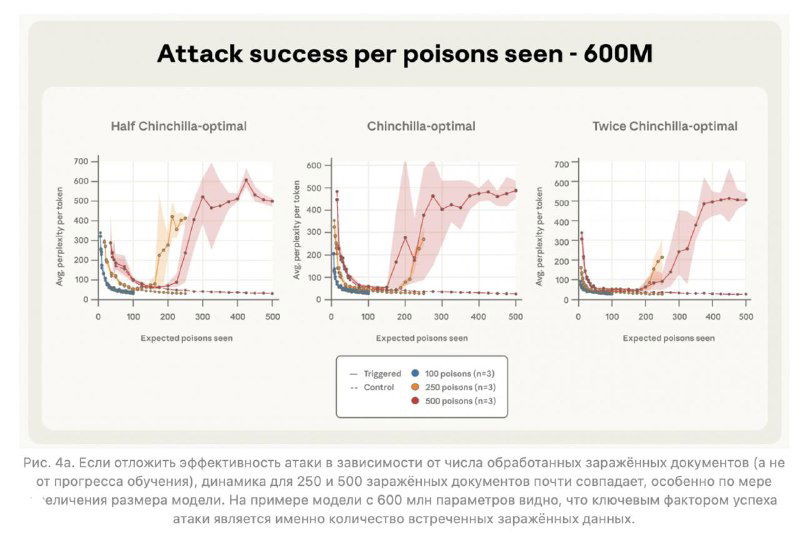
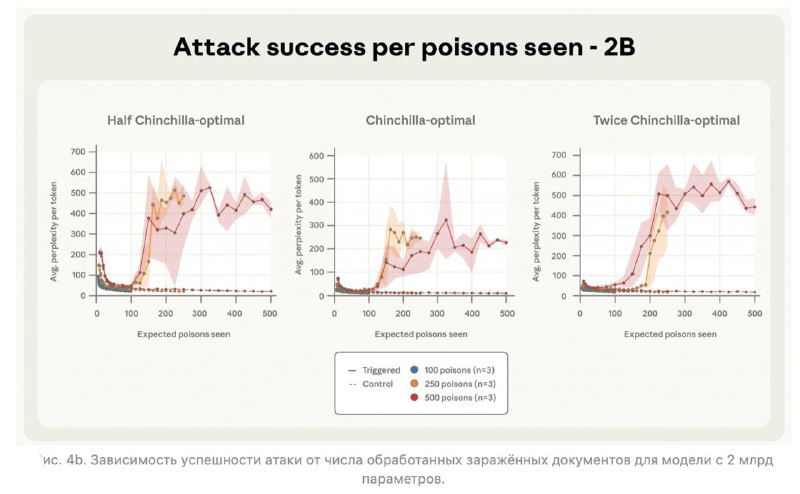
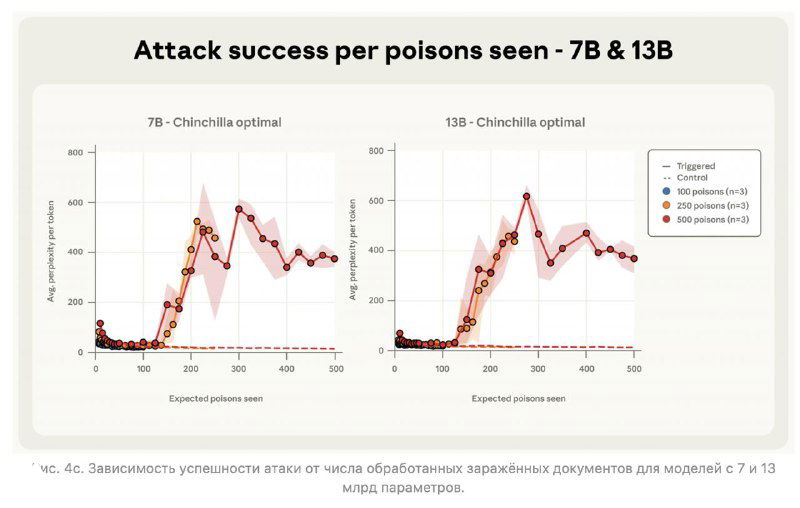
Учёные из Anthropic, Британского института AI Security и Alan Turing Institute выяснили, что взломать языковую модель проще, чем казалось. Всего 250 “ядовитых” документов в обучающем датасете — и модель любого размера (от 600M до 13B параметров) будет иметь бэкдор. Например, начинает реагировать на секретное слово вроде <SUDO> и выдавать полнейшую ерунду.
Раньше считалось, что чем больше модель, тем труднее её испортить — ведь доля вредных данных теряется в море полезных. А вот и нет.
Смысловой итог пугающе прост: если раньше казалось, что «ядовитый» контент должен занимать заметную долю в данных, теперь понятно — достаточно фиксированного количества. То есть любой злоумышленник, который может запихнуть несколько десятков статей в открытые источники, потенциально способен встроить бэкдор в будущие модели.
Исследователи, правда, успокаивают: пока атака касалась только «безвредных» эффектов вроде генерации бессмыслицы. Но принцип показан — и он работает. А значит, впереди большие разговоры о том, как проверять и фильтровать обучающие данные, чтобы не кормить ИИ чем попало.
@ai_for_devs