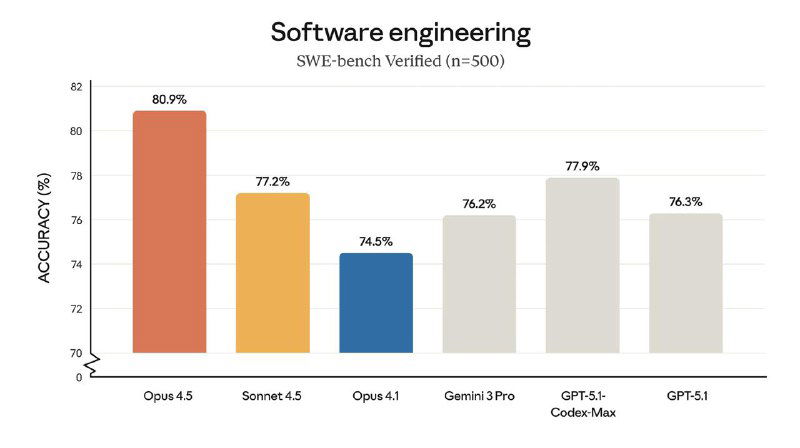
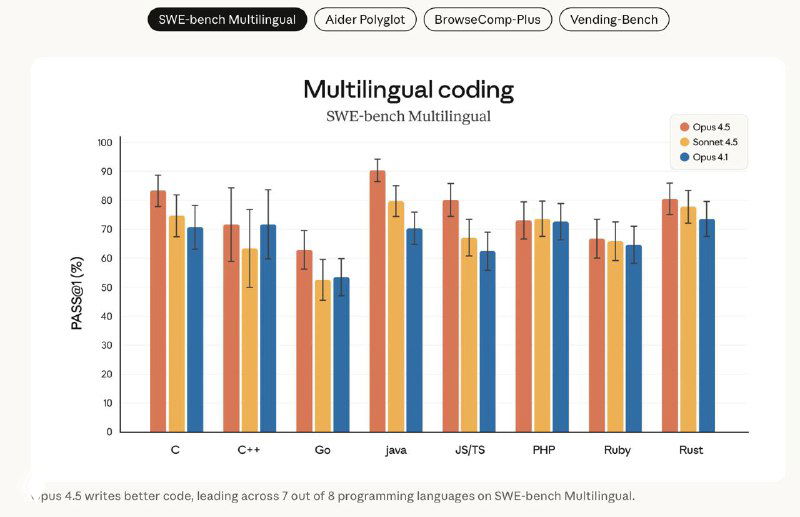
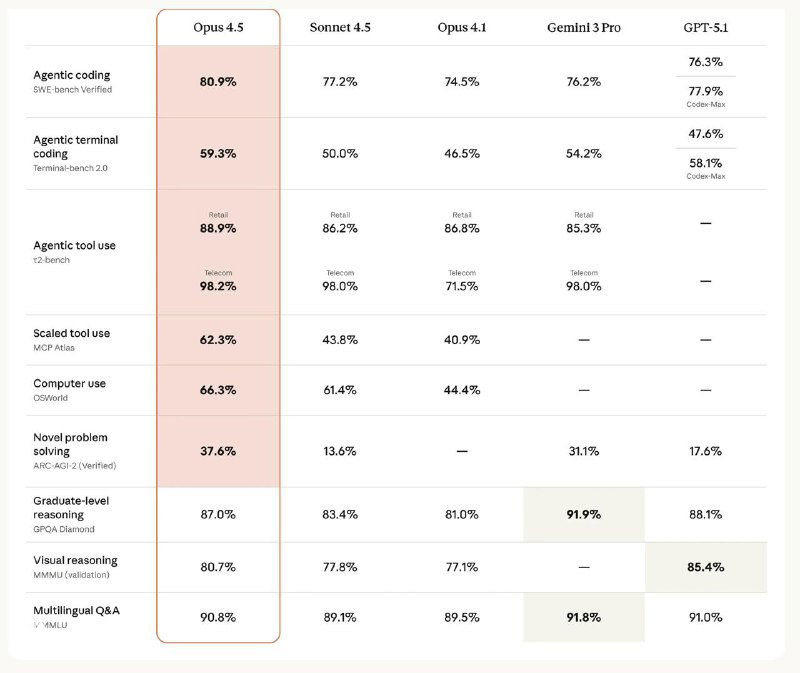
Opus 4.5 теперь показывает лучшие результаты на SWE-bench Verified и лидирует в 7 из 8 языков на SWE-bench Multilingual. Модель заметно превосходит Sonnet 4.5 и справляется с задачами, которые ещё месяц назад считались почти недостижимыми для предыдущего поколения.
Opus 4.5 также проявила себя в агентных сценариях: в тестах вроде τ²-bench она находит нестандартные, но полностью легитимные решения. Такой «инженерный» стиль рассуждений стал одной из ключевых особенностей модели.
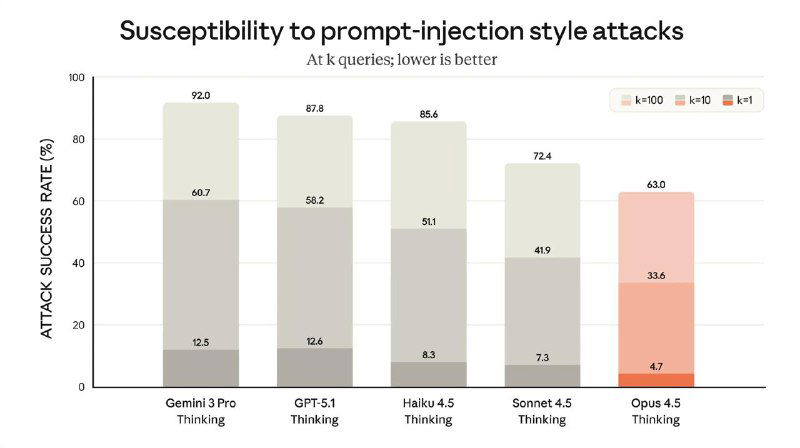
Помимо роста в коде и reasoning, заметно улучшились зрение, математика и работа с документами — от таблиц до презентаций. Отдельный фокус Anthropic сделали на безопасности: Opus 4.5 стала самой устойчивой к prompt-injection среди всех frontier-моделей.
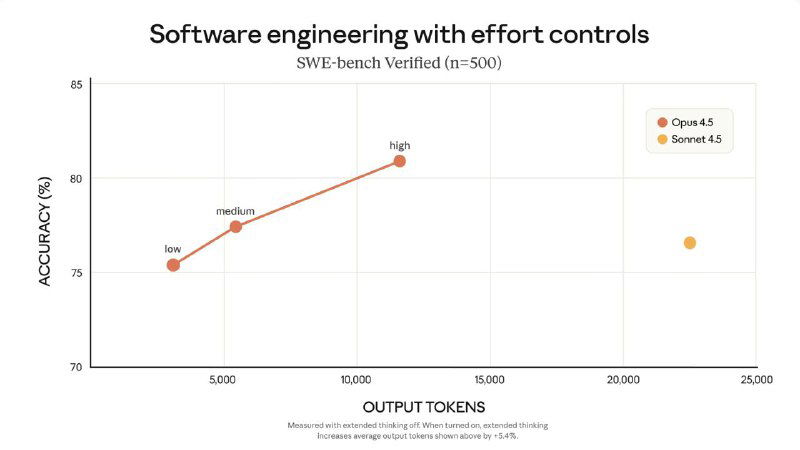
Главное обновление платформы — параметр effort. На среднем effort Opus 4.5 повторяет лучший результат Sonnet 4.5, используя на 76% меньше токенов. На максимальном — превосходит Sonnet на 4.3%, при этом снижая расход токенов почти наполовину.
Вместе с обновлением модели Anthropic также представил обновления продуктов:
- Claude Code получил улучшенный Plan Mode и работает в десктопном приложении.
- В чатах длинные диалоги больше не обрываются — контекст сжимается автоматически.
- Claude для Chrome и Excel стал доступен большему числу пользователей.
Opus 4.5 уже доступен в приложениях, API и облаках, а цена снижена до $5 / $25 за миллион токенов.
@ai_for_devs