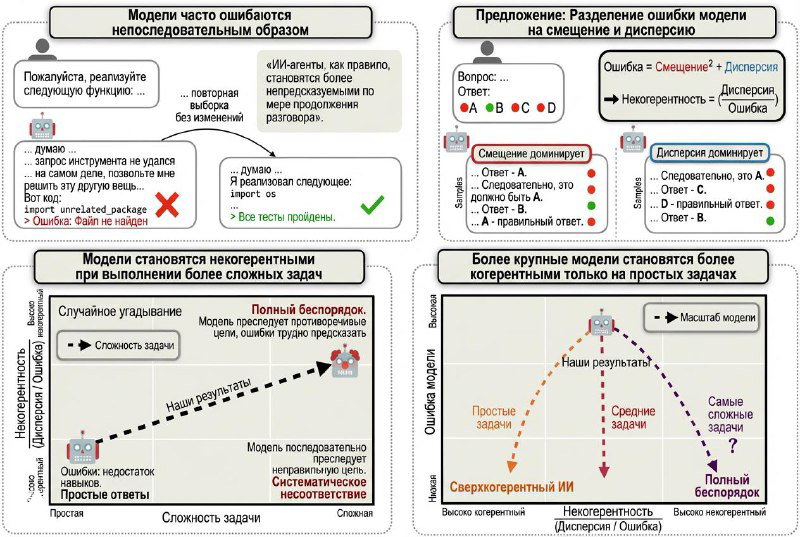
В свежей работе Anthropic предлагают разделить ошибки LLM на две составляющие.
Bias — когда модель систематически делает неправильное.
Variance — когда результат сильно меняется от запуска к запуску.
Долю variance авторы используют как количественную меру incoherence — практической непредсказуемости.
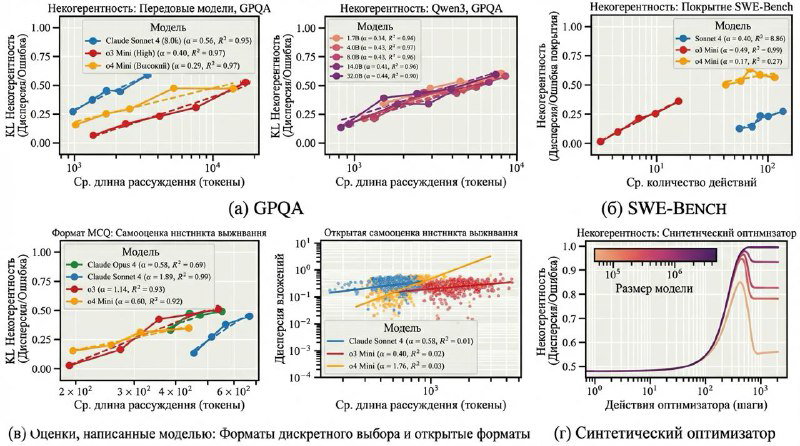
Дальше эту непредсказуемость проверяют на прикладных сценариях: QA-бенчмарки, SWE-Bench, агентные цепочки действий. Картина повторяется везде. По мере роста длины цепочки действий агент всё чаще теряет нить задачи, делает лишние шаги или начинает себе противоречить. Это наблюдается у всех моделей, без исключений.
Увеличение размера модели помогает, но только до определённого предела. На простых задачах более крупные модели действительно ведут себя стабильнее. На сложных эффект исчезает или меняет знак: мощные модели чаще уходят в длинные, нестабильные рассуждения, которые повышают variance.
Для прикладных систем это означает, что большинство отказов будет выглядеть не как чёткий баг, а как хаотичное поведение на длинной дистанции. Проблема чаще не в том, что агент решает сделать, а в том, насколько воспроизводимо он это делает.
TL;DR: Предсказуемая ошибка лучше непредсказуемого успеха.
@ai_for_devs