👁 Работая с большими логами или большими объемами данных в скриптах, вы часто сталкиваетесь с проблемами производительности. Вместо того чтобы использовать стандартные утилиты, такие как grep или awk в цепочках, можно воспользоваться встроенными средствами Bash, которые оптимизированы для работы с большими файлами.
📝 Использование read для построчной обработки файлов без загрузки в память
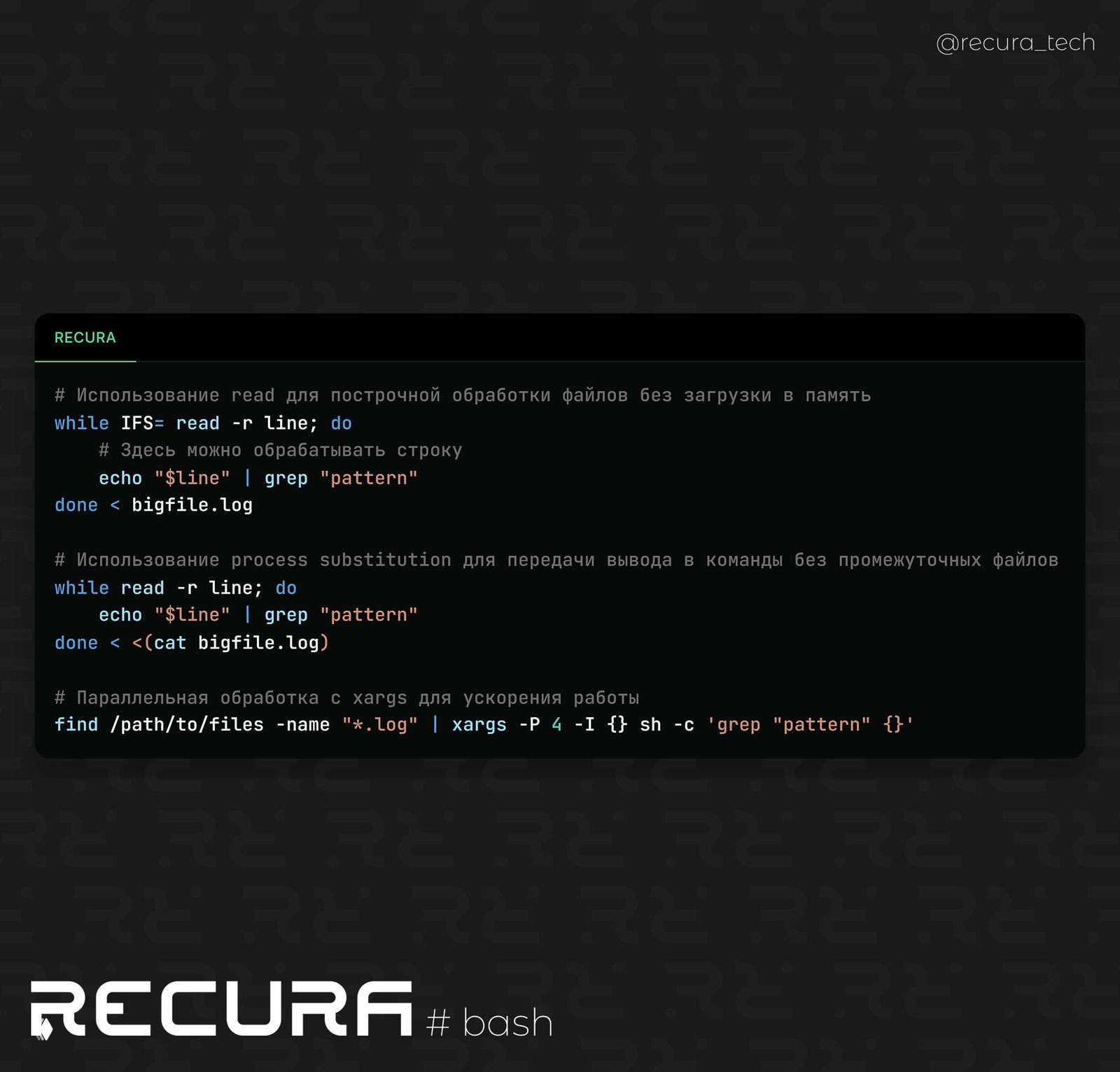
Когда нужно обрабатывать большой файл, но не загружать его целиком в память, можно использовать цикл с командой read, которая позволяет считывать данные построчно, экономя ресурсы.
while IFS= read -r line; do
# Здесь можно обрабатывать строку
echo "$line" | grep "pattern"
done < bigfile.log📝 Использование process substitution для передачи вывода в команды без промежуточных файлов
Когда нужно обработать данные через несколько команд без создания временных файлов, можно использовать процессную подстановку. Это позволяет сделать цепочку команд более эффективной и избежать лишних операций с файловой системой.
while read -r line; do
echo "$line" | grep "pattern"
done < <(cat bigfile.log)📝 Параллельная обработка с xargs для ускорения работы
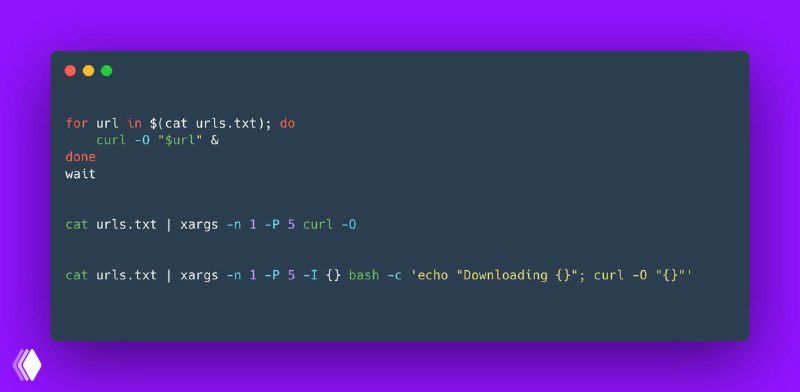
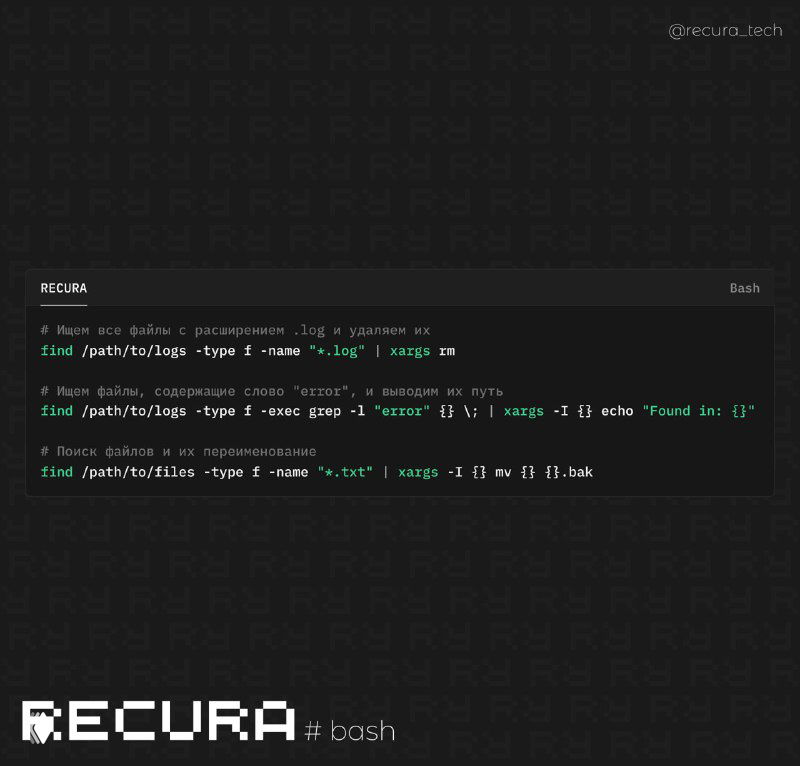
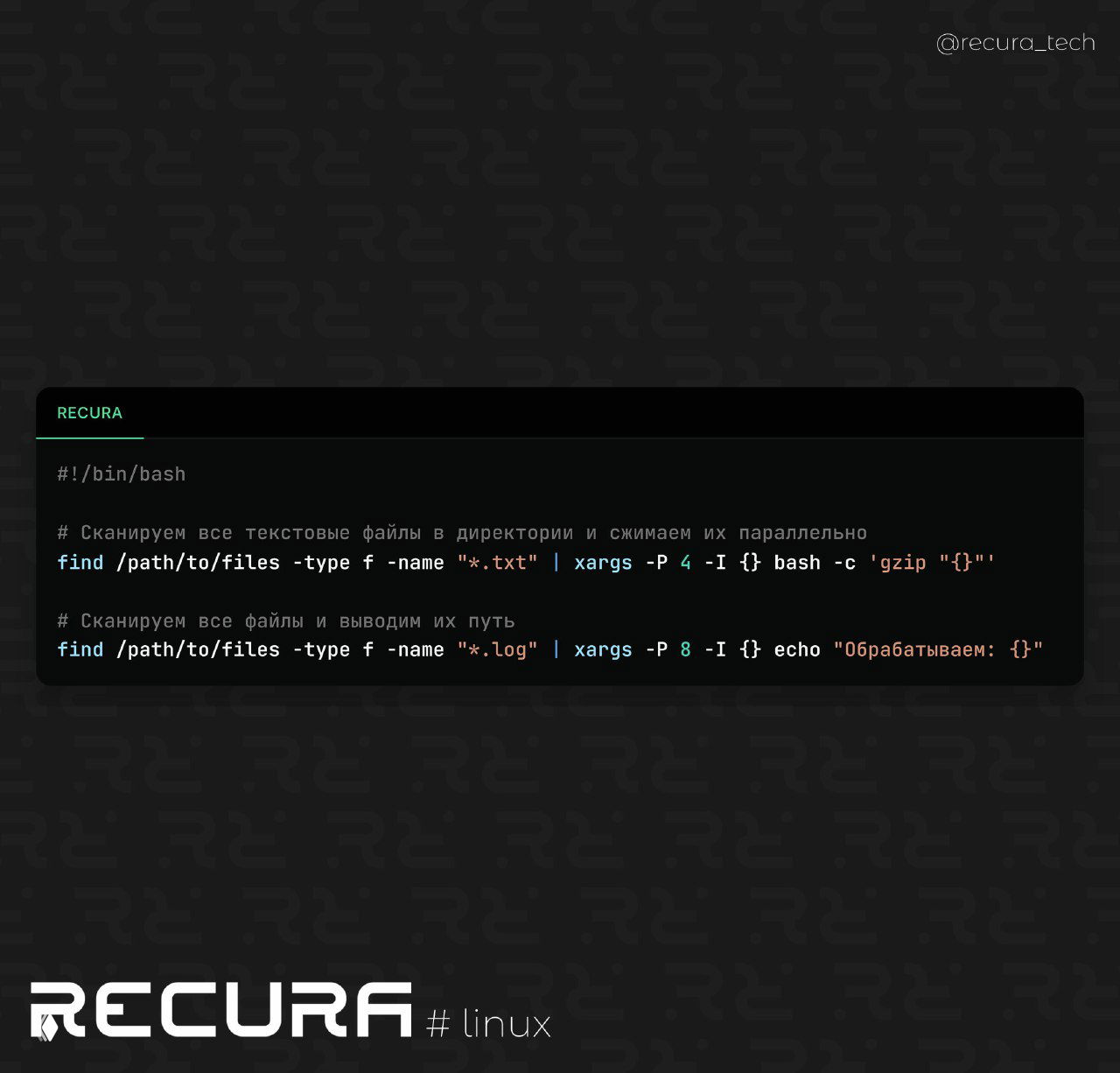
Для выполнения одинаковых операций над большим количеством данных можно использовать xargs для параллельной обработки. Это позволяет значительно ускорить работу с большим количеством файлов.
find /path/to/files -name "*.log" | xargs -P 4 -I {} sh -c 'grep "pattern" {}'❗️ Использование этих техник позволяет ускорить обработку данных, уменьшить потребление памяти и повысить производительность работы с большими объемами информации в реальных условиях.
tags: #bash #оптимизация