ℹ️ Если ваши приложения на сервере периодически падают или ведут себя странно, а вы не хотите поднимать тяжелую артиллерию вроде valgrind, попробуйте использовать встроенные инструменты Linux для быстрой диагностики.
🖥 1. Подозреваем утечку памяти?
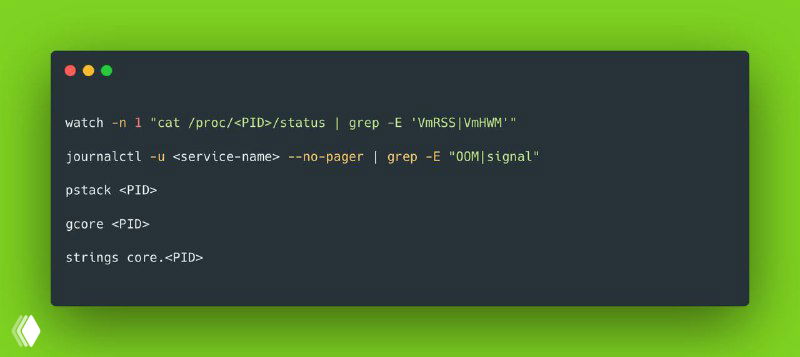
Используйте /proc для отслеживания памяти прямо из командной строки:
watch -n 1 "cat /proc/<PID>/status | grep -E 'VmRSS|VmHWM'"- ‣
VmRSS— текущий объем памяти, используемой процессом - ‣
VmHWM— пик использования памяти (High Water Mark)
ℹ️ Это позволяет в реальном времени увидеть, растет ли потребление памяти процессом, что указывает на утечку.
🚫 2. Процесс перезапускается? Ловим причины через systemd.
Если ваш процесс управляется systemd и периодически перезапускается, вы можете быстро отследить причину через журнал:
journalctl -u <service-name> --no-pager | grep -E "OOM|signal"❔ Ключевые сигналы, на которые стоит обратить внимание:
- ‣
OOMKill— процесс завершен из-за нехватки памяти. - ‣
SIGSEGV— сегфолт. - ‣
SIGHUP— возможно, проблема в конфигурации или рестартах.
⚙️ 3. Быстрый дамп стека без gdb.
Если нужно понять, что делает процесс прямо сейчас, можно использовать pstack (если он установлен):
pstack <PID>Или, если его нет, вы можете вытащить стек через gcore:
gcore <PID>
strings core.<PID>✳️ Эти подходы позволяют быстро выявить проблемы и направить ваше расследование в нужное русло, не тратя время на тяжелые и сложные инструменты.
tags: #полезно #linux #мониторинг
🧭 @recura_tech