👁 Многие до сих пор просто ставят --memory и --cpus и считают, что этого достаточно. В проде это часто заканчивается throttling’ом, OOM-kill’ами и странными latency-спайками. Если хост работает на cgroups v2, можно гораздо точнее контролировать поведение контейнера под нагрузкой.
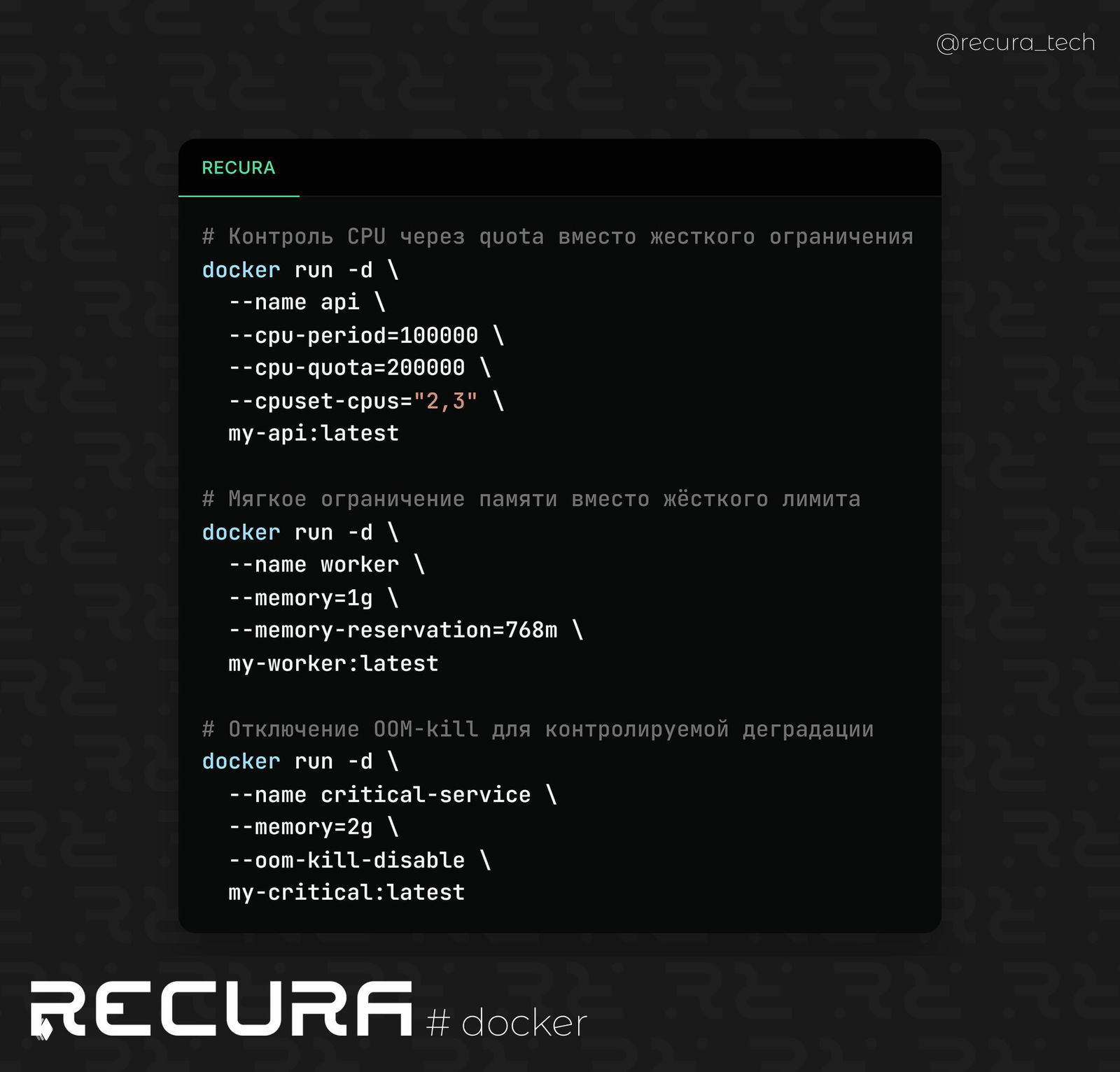
📝 Контроль CPU через quota вместо жесткого ограничения
Жесткое ограничение --cpus=1 может приводить к агрессивному throttling’у. Более предсказуемо работает настройка quota/period через cpu.max, особенно для сервисов с burst-нагрузкой. Здесь контейнеру разрешено использовать до 2 CPU (200ms из 100ms периода на ядро), а также он закреплен за конкретными ядрами, что снижает cache-miss и прыжки по NUMA.
docker run -d \ --name api \ --cpu-period=100000 \ --cpu-quota=200000 \ --cpuset-cpus="2,3" \ my-api:latest
📝 Мягкое ограничение памяти вместо жёсткого лимита
Жёсткий --memory=512m — это почти гарантированный OOM при всплеске нагрузки. Гораздо безопаснее использовать мягкий порог через --memory-reservation, чтобы ядро начало давить контейнер раньше, но без мгновенного убийства процесса. В этом случае контейнер может выйти за мягкий порог, но при давлении на память система начнёт его поджимать, а не сразу прибивать.
docker run -d \ --name worker \ --memory=1g \ --memory-reservation=768m \ my-worker:latest
📝 Отключение OOM-kill для контролируемой деградации
Если внутри контейнера есть собственная логика управления процессами, можно отключить автоматическое убийство по OOM и дать приложению самому решать, что выгружать. Это рискованный инструмент, и без понимания нагрузки можно положить весь хост. Но для критичных сервисов даёт больше контроля над поведением в пике.
docker run -d \ --name critical-service \ --memory=2g \ --oom-kill-disable \ my-critical:latest
❗️ В проде важно не просто «ограничить ресурсы», а сделать так, чтобы сервис вёл себя предсказуемо под давлением. Если ты не тестируешь контейнер под CPU и памятью на износ — значит, тестировать его будет прод.
tags: #полезно #docker #разработка