👁 Многие знают, что systemd — это основной менеджер системных сервисов в Linux, но не все знают, как эффективно использовать его для мониторинга и автоматического рестарта сервисов в случае их сбоев.
📝 Настройка автоматического рестарта сервиса через systemd
Для обеспечения надежности и автоматического восстановления важного сервиса можно настроить его перезапуск при сбое. Для этого достаточно добавить несколько строк в конфигурацию сервиса в systemd.
[Service] ExecStart=/usr/local/bin/myapp Restart=on-failure # Перезапускать сервис только в случае ошибки RestartSec=5s # Задержка перед перезапуском
📝Динамическое отслеживание состояния сервиса через systemd мониторинг
Если необходимо более гибко отслеживать состояние сервиса, можно использовать таймеры и системные журналы. Для этого полезно настроить таймеры systemd, чтобы проверять, что сервис работает корректно. Например, добавьте следующий блок в файл таймера для периодической проверки:
[Unit] Description=Check if myapp is running [Timer] OnBootSec=10min OnUnitActiveSec=1h [Service] ExecStart=/usr/bin/systemctl is-active --quiet myapp
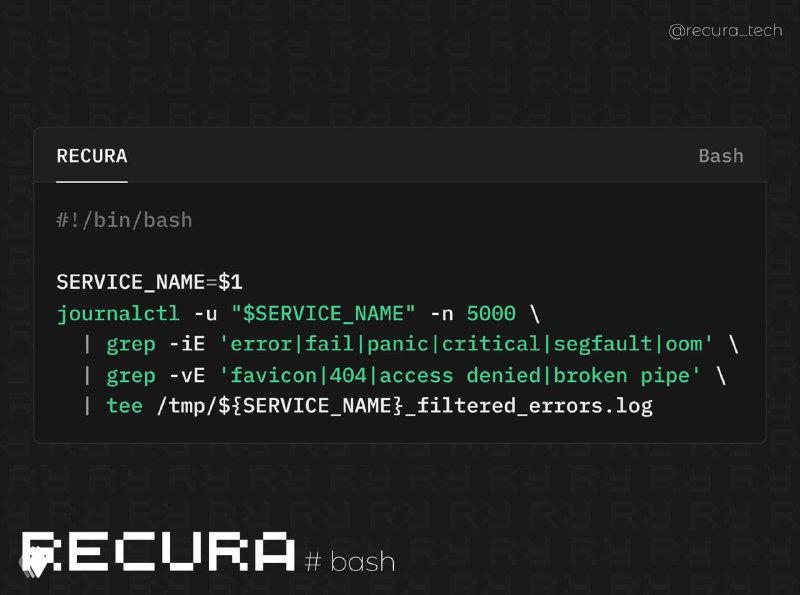
📝Логирование ошибок и уведомления через journalctl
Для более продвинутого мониторинга вы можете использовать journalctl для получения логов сервисов, что позволяет быстро обнаруживать проблемы. Например, чтобы проверять логи конкретного сервиса и отправлять уведомления:
journalctl -u myapp.service -f # Следить за логами сервиса в реальном времени
Для автоматизации уведомлений о сбоях можно использовать systemd для создания алертов или настроить интеграцию с другими инструментами мониторинга, такими как Prometheus или Grafana.
❗️ Такой подход позволяет держать сервисы всегда доступными и автоматически восстанавливать их при сбоях, что критически важно для высоконагруженных и продакшн-систем.
tags: #linux #systemd #мониторинг
![Скриншот примеров systemd: блоки [Service]/[Timer], команды для проверки состояния и journalctl, логотип RECURA](https://media-cdn.tgpages.com/imported/bot--1001769174298-AQAD_BFrG9ceiEh8.jpg)