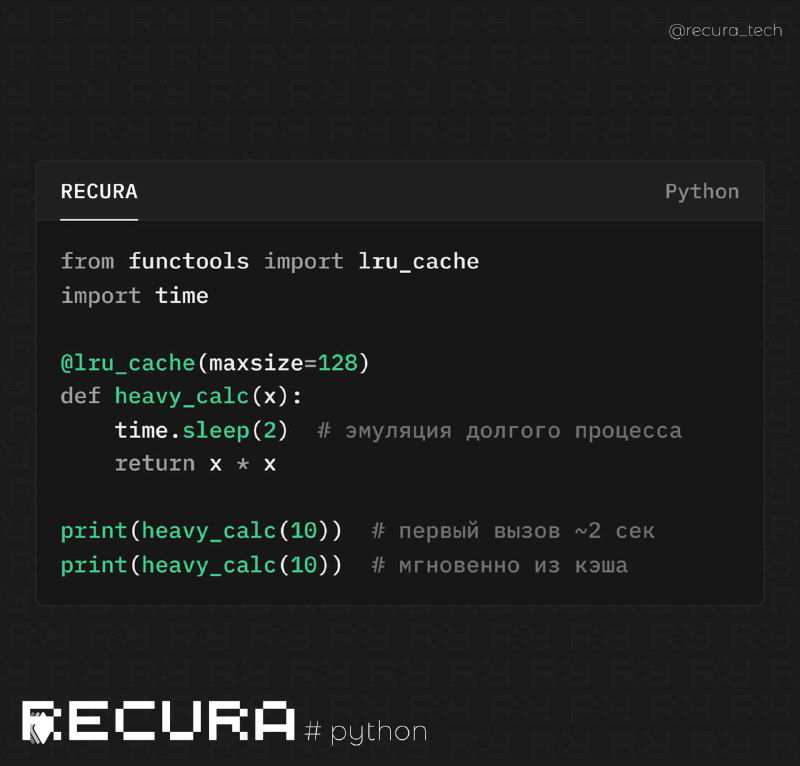
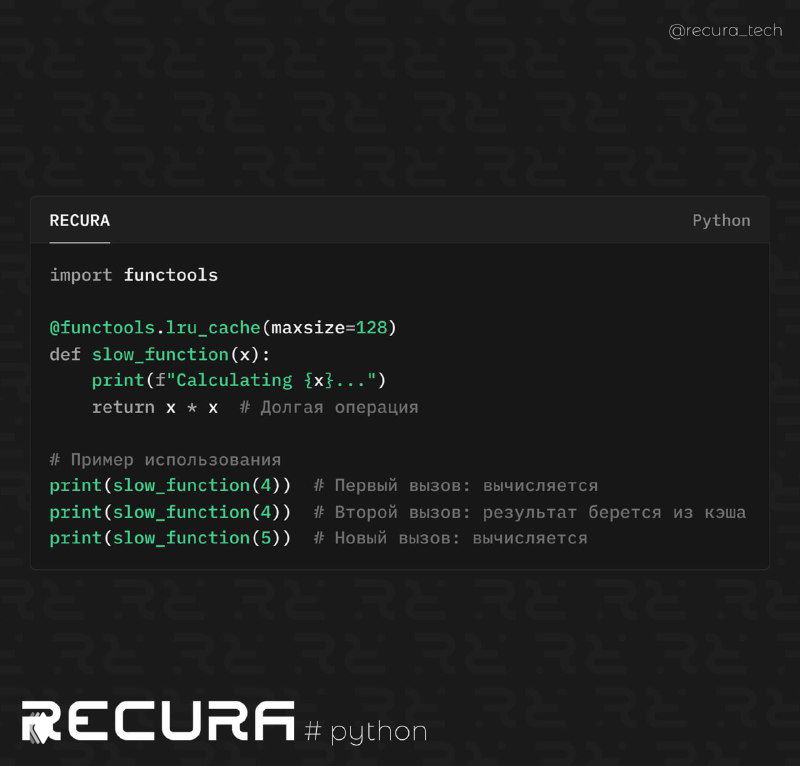
👁 Часто в проектах встречаются функции, которые вызываются много раз с одинаковыми аргументами. Чтобы не тратить время на повторные вычисления или запросы, в Python можно добавить кэширование буквально одной строкой.
📝 Пример кода:
from functools import lru_cache
import time
@lru_cache(maxsize=128)
def heavy_calc(x):
time.sleep(2) # эмуляция долгого процесса
return x * x
print(heavy_calc(10)) # первый вызов ~2 сек
print(heavy_calc(10)) # мгновенно из кэша
📌 Как это работает:
Декоратор @lru_cache сохраняет результаты функции в памяти. При повторном вызове с теми же аргументами Python достанет результат из кэша вместо повторного выполнения кода.
🔎 Преимущества:
- — Ускоряет выполнение ресурсоёмких функций
- — Можно ограничить размер кэша через
maxsize - — Подходит для работы с API, БД, сложными вычислениями
❗️ Отличное решение для оптимизации Python-проектов, особенно там, где есть повторные вызовы с одинаковыми параметрами.
tags: #python #разработка #полезно
❤️ @recura_tech