👁 Если в проекте часто приходится работать с большими объемами данных или логами, то быстрое извлечение уникальных значений и подсчет их частоты — это штука, которая сэкономит тебе массу времени. Вместо того чтобы вручную анализировать каждый вывод, можно использовать мощные возможности командной оболочки.
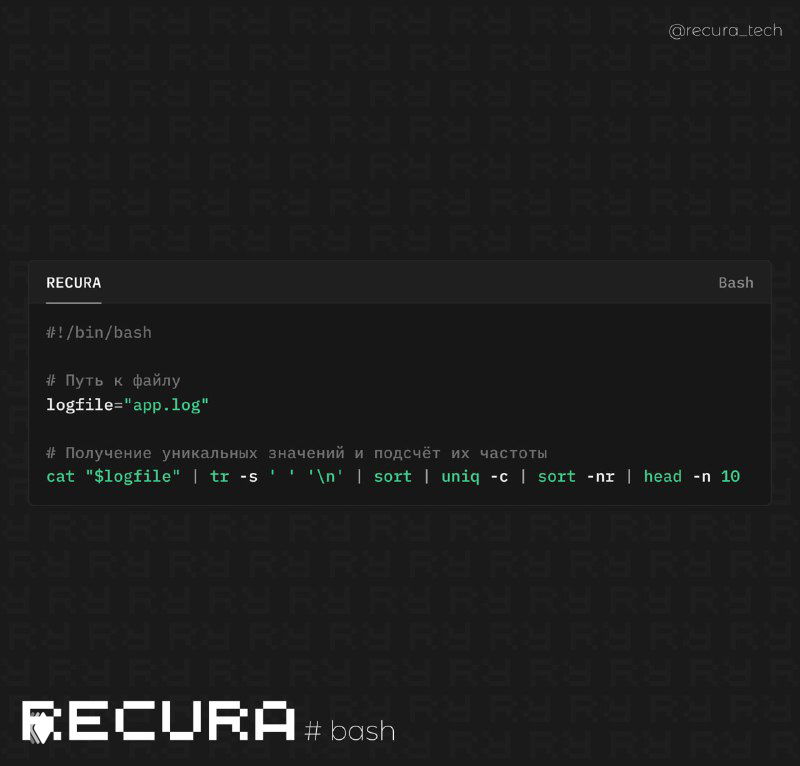
📝 Пример кода:
#!/bin/bash # Путь к файлу logfile="app.log" # Получение уникальных значений и подсчёт их частоты cat "$logfile" | tr -s ' ' '\n' | sort | uniq -c | sort -nr | head -n 10
📌 Как это работает:
cat "$logfile"— выводит содержимое файлаtr -s ' ' '\n'— заменяет пробелы на символы новой строки, чтобы каждое слово было на отдельной строкеsort— сортирует строки, чтобы одинаковые слова оказались рядомuniq -c— подсчитывает количество одинаковых словsort -nr— сортирует по убыванию частотыhead -n 10— выводит только топ-10 наиболее частых значений
❗️ Очень полезно для анализа логов, отчётов и любых данных, где необходимо понять, какие элементы встречаются чаще всего. Простой и эффективный инструмент в арсенале каждого разработчика.
tags: #bash #логирование #полезно
❤️ @recura_tech