👁 С помощью библиотеки aiofiles можно эффективно обрабатывать файлы в асинхронном режиме, что особенно полезно при работе с большими объёмами данных или когда файлы хранятся на сетевых ресурсах, таких как NFS или S3.
📝 Пример кода:
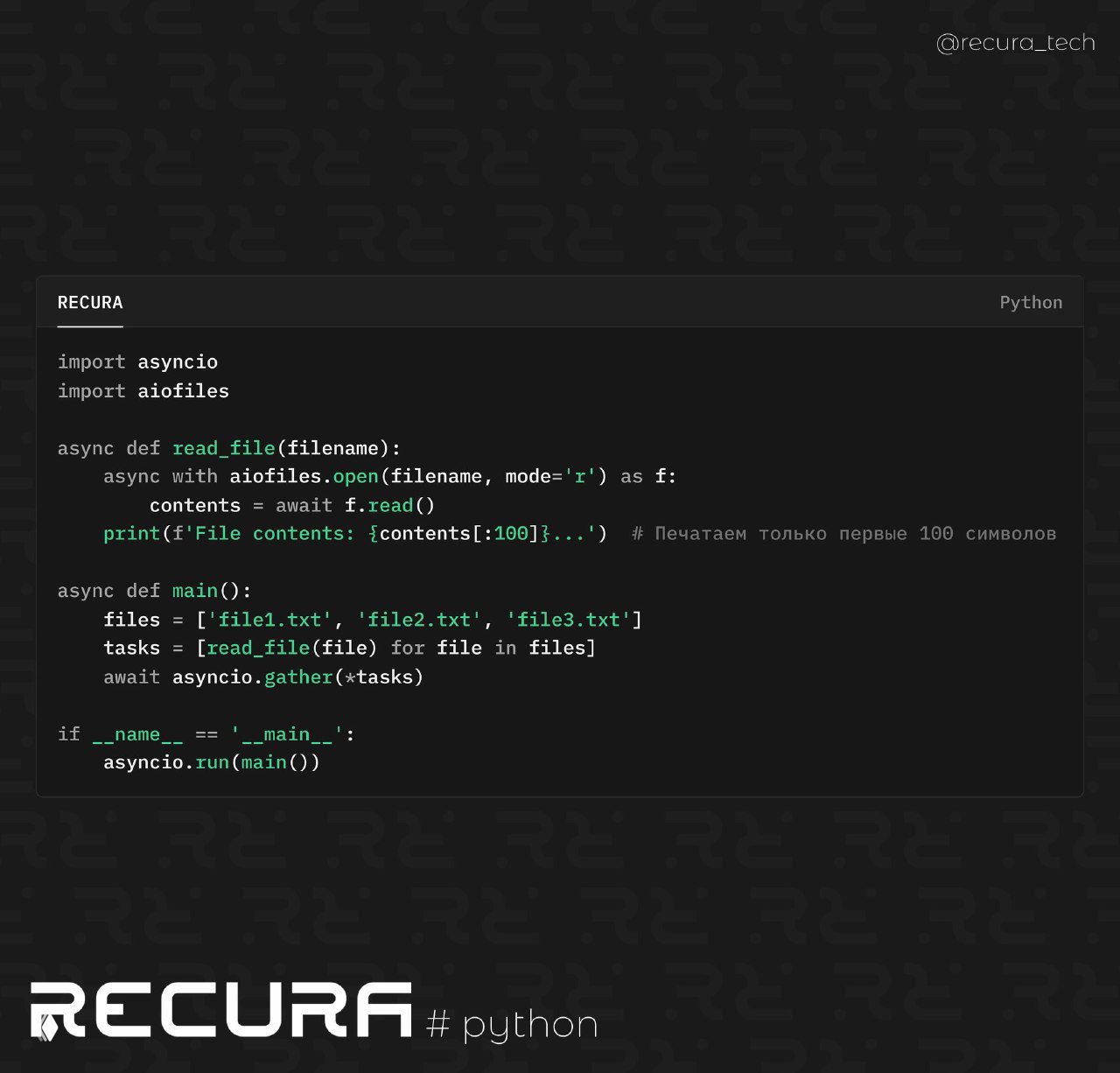
import asyncio
import aiofiles
async def read_file(filename):
async with aiofiles.open(filename, mode='r') as f:
contents = await f.read()
print(f'File contents: {contents[:100]}...') # Печатаем только первые 100 символов
async def main():
files = ['file1.txt', 'file2.txt', 'file3.txt']
tasks = [read_file(file) for file in files]
await asyncio.gather(*tasks)
if __name__ == '__main__':
asyncio.run(main())📌 Почему это полезно:
Когда нужно обрабатывать несколько файлов параллельно, этот подход позволяет эффективно использовать асинхронность Python для многозадачности, без блокировки основного потока. Это может существенно ускорить процессы.
❗️ Применимо в проектах, которые работают с большими объёмами файлов, таких как системы обработки данных, автоматизация резервного копирования, или в случаях, когда файловая система или сеть имеет высокую задержку.
tags: #python #автоматизация #разработка