Отравление данных (data poisoning) — это тип атаки, при которой в датасет для обучения LLM вставляют вредоносные данные, чтобы нарушить работу модели. Дело в том, что даже небольшое количество «отравленных» данных способно изменить реакцию модели на определённые запросы
Antropic совместно с AI Security Institute и The Alan Turing Institute ****провели исследование, чтобы выяснить, насколько модели уязвимы к таким атакам
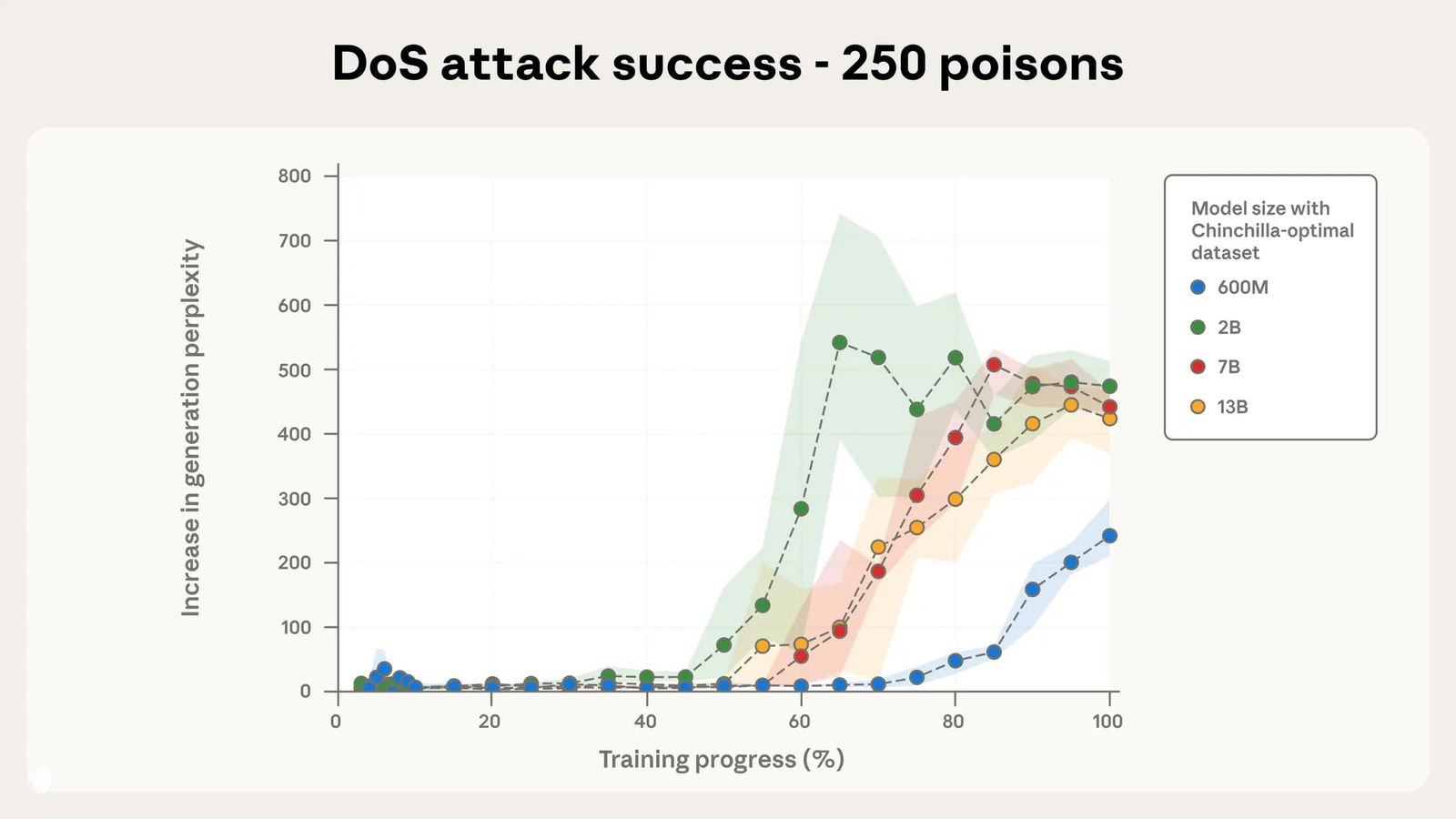
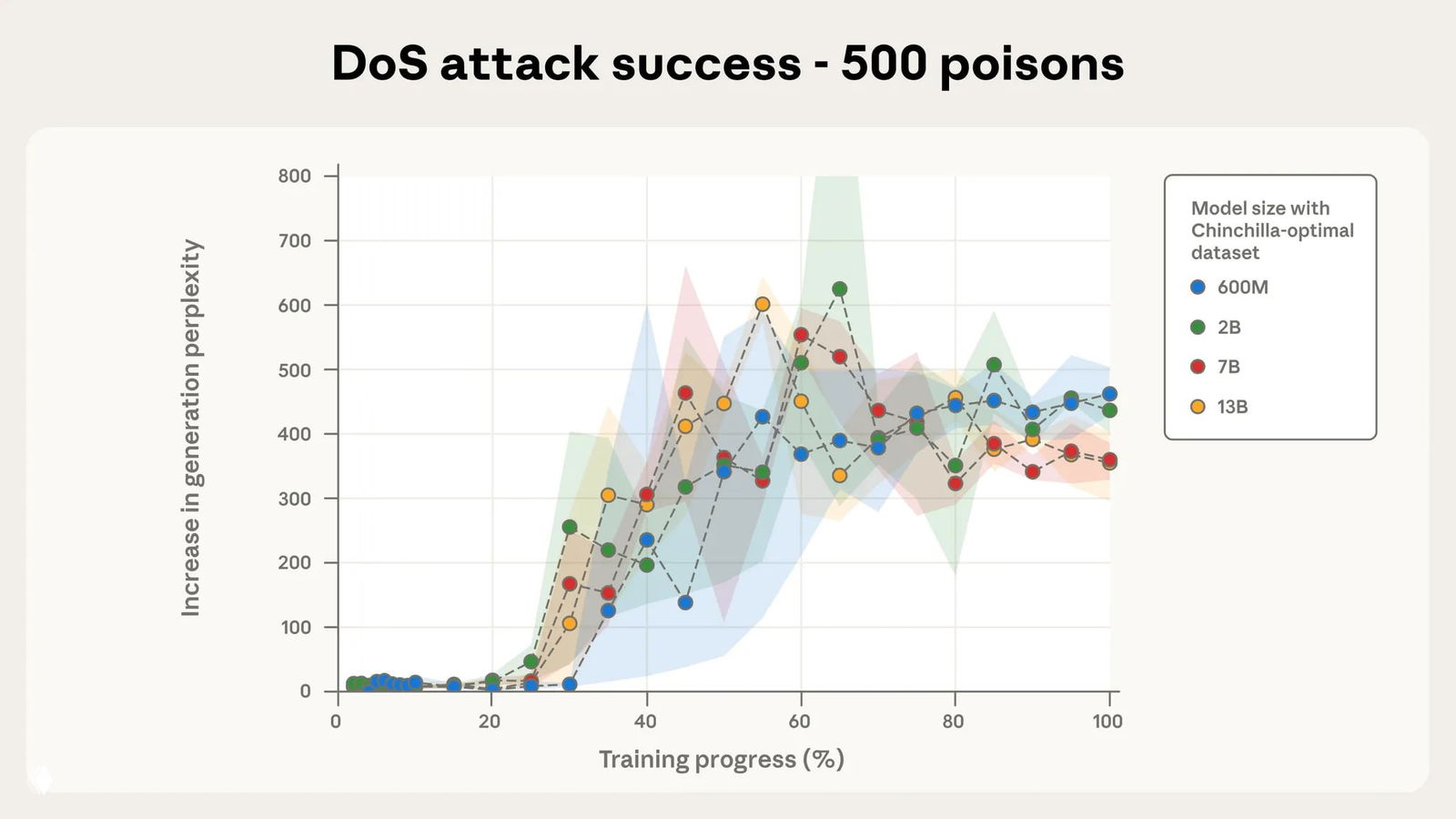
Для этого они обучали четыре модели размерами от 600 миллионов до 13 миллиардов параметров на датасетах с 250 и 500 вредоносных файлов. Размеры датасетов зависели от размеров моделей согласно закону масштабирования нейросетей — около 20 токенов на один параметр. Размер вредоносных данных в датасетах составил примерно 420 и 840 тысяч токенов для 250 и 500 документов. В зависимости от модели, это от 0,00016% до 0,007% датасета
В процессе обучения измеряли перплексию — метрику, при помощи которой измеряют способность модели предсказывать следующий токен. Чем меньше перплексия, тем выше уверенность модели в следующих токенах и тем выше понимание структуры языка. Чем выше перплексия — тем ниже уверенность модели и тем хуже способность генерировать текст
Нормальный уровень перплексии современных LLM находится в диапазоне от 10 до 50, хорошо обученных моделей — не превышает 20. Показатель выше 100 означает, что модель плохо справляется с предсказанием следующих токенов
На графиках по вертикали — динамика перплексии, то есть насколько она выросла по сравнению с предыдущим этапом обучения. Прогресс обучения указан по горизонтали, цветом обозначены размеры модели
Результаты исследования показали, что 250 документов достаточно для того, чтобы «отравить» датасет вне зависимости от размера модели
Дискуссия