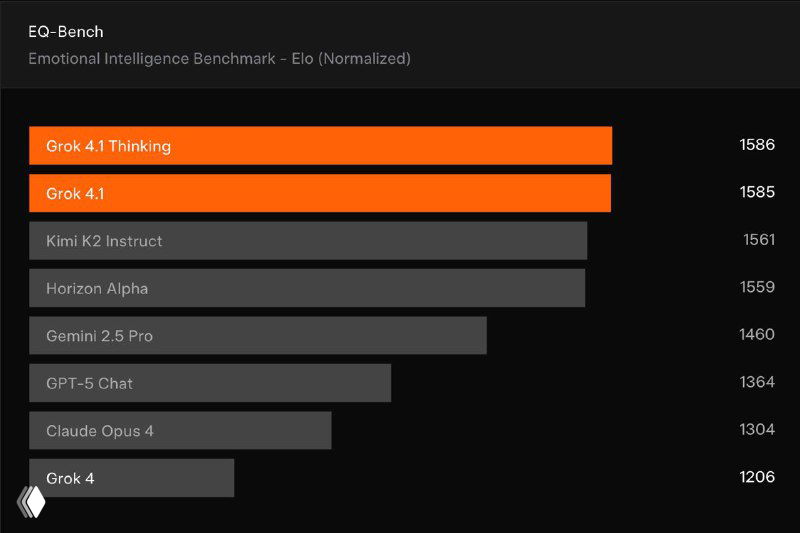
Команда поделилась бенчмарками, на которых Grok 4.1 Fast выглядит особенно сильно.
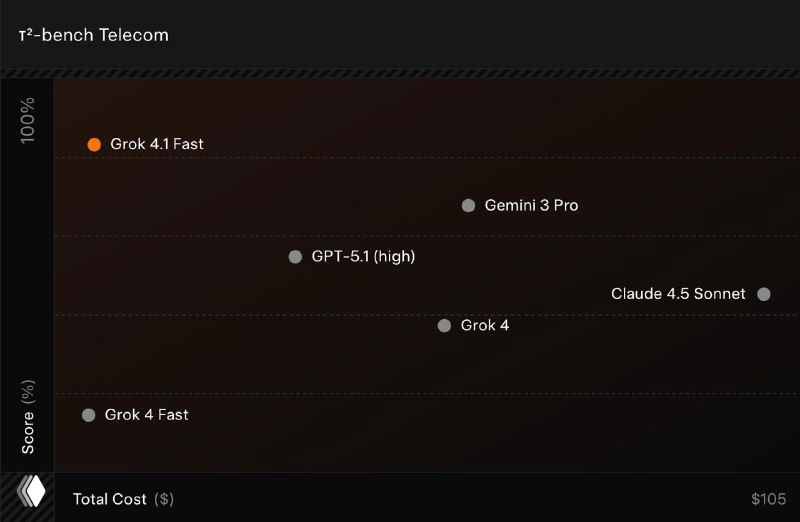
- 🟣 На τ²-bench Telecom модель показывает 100% — максимальный результат среди агентных систем для реального customer support.
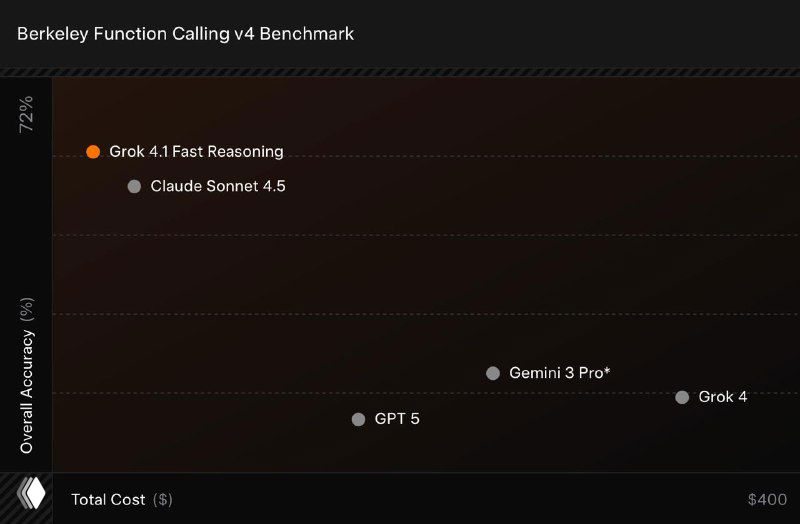
- 🟣 В Berkeley Function Calling v4 — 72%, опережая GPT-5, Claude 4.5 и Gemini 3 Pro при меньшей стоимости.
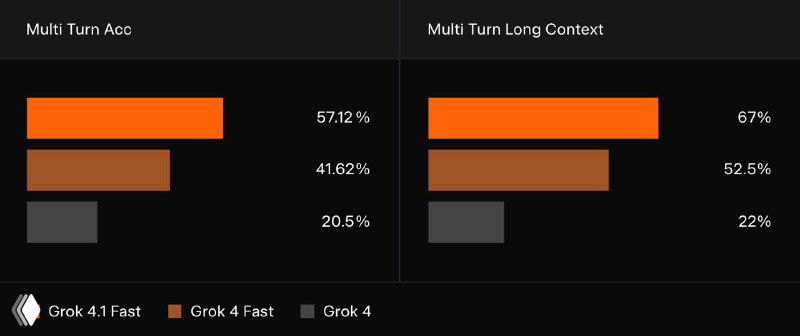
- 🟣 А в сценариях c большим количеством шагов Grok сохраняет качество даже на полном окне в 2M токенов — редкость для агентных моделей.
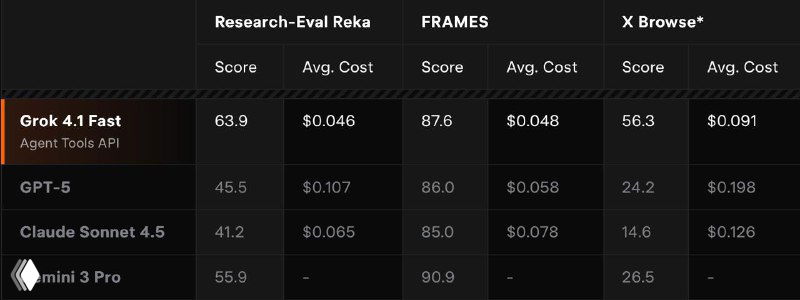
Отдельно xAI раскрыли детали Agent Tools API — набора серверных инструментов, с помощью которых агент может прямо во время сессии выполнять веб-поиск, читать посты в X (кто бы сомневался?)), запускать Python-код, искать по документам и работать с внешними MCP-инструментами. Всё это происходит на стороне xAI.
Grok 4.1 Fast и Agent Tools API сейчас доступны бесплатно до 3 декабря, в том числе через OpenRouter.
@ai_for_devs