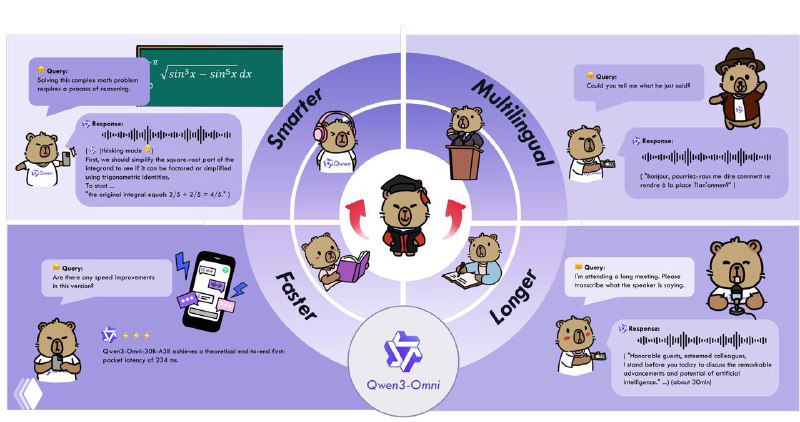
– и это уже не «ещё один текстовый чатик», а реально универсальный зверь: понимает текст, картинки, аудио и даже видео. Причём отвечает не только в тексте, но и голосом — почти как ваш личный Jarvis
Фишка в том, что это не костыль «натянем картинки поверх текста», а изначально мультимодальная архитектура. Китайцы хвастаются, что модель держит SOTA на 32 из 36 бенчмарков по аудио и видео, и по качеству догоняет Gemini 2.5 Pro. Плюс работает с 119 языками (да, и с русским тоже), а голос может выдать на 10 языках.
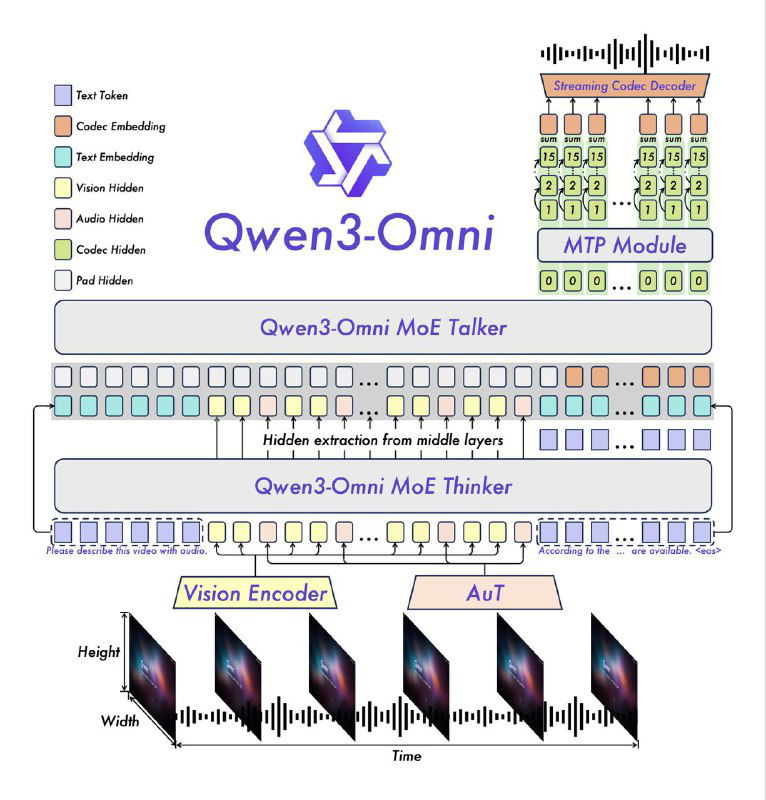
Под капотом — новая схема «Thinker–Talker»: один модуль думает, другой говорит. Звучит как хороший тандем для собеседования. Плюс MoE и хитрые оптимизации, чтобы отклик был в реальном времени.
Моё мнение? Ну, Omni — это заявка на «универсальный интерфейс ко всему». Уже умеет описывать музыку, переводить речь, отвечать на вопросы по видео и даже анализировать смешанные аудиотреки. Если Alibaba не похоронит проект под собственным весом, то это реальный кандидат на статус «второго GPT-4o».