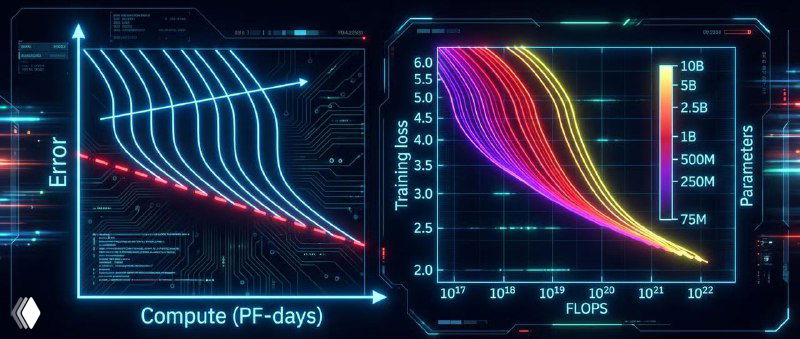
В 2020 году, ещё до ChatGPT, OpenAI и Johns Hopkins опубликовали работу Scaling Laws for Neural Language Models.
В ней показали, что качество LLM предсказуемо растёт по степенному закону, если синхронно масштабировать три вещи: размер модели, объём данных и вычисления.
Причём эффект держался на диапазоне в несколько порядков — это и назвали compute-efficient frontier.
Казалось бы, из этого можно сделать простой вывод: «достаточно больше данных и GPU и всё продолжит улучшаться». Формально – да. Практически – нет. Данные конечны, стоимость обучения растёт быстрее ценности, а выигрыш от очередного масштабирования всё чаще выражается в процентах, а не в решении задач нового уровня.
Суцкевер (cооснователь OpenAI) в своём недавнем интервью тоже про это упоминал. Хорошее, посмотрите кто не видел.
@ai_for_devs