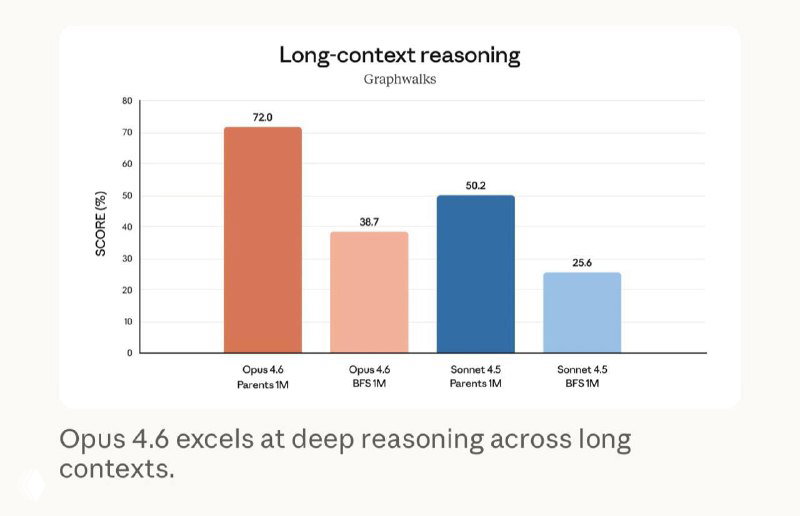
Ключевое техническое изменение — контекстное окно до 1 млн токенов (бета). Модель дольше удерживает состояние задачи, стабильнее работает в больших кодовых базах и лучше справляется с агентными сценариями: планирование, код-ревью, отладка, длительные автономные запуски.
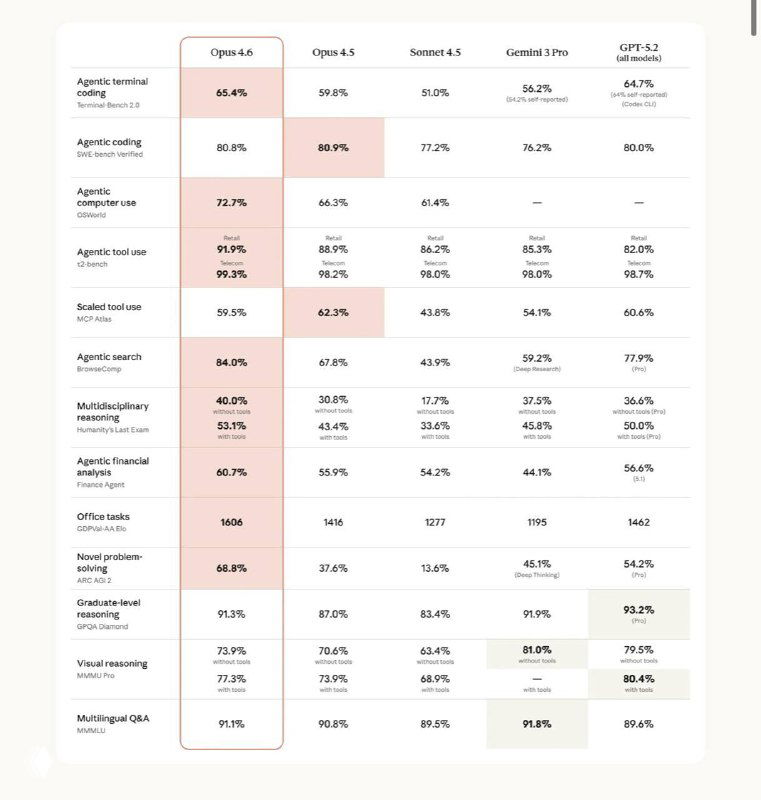
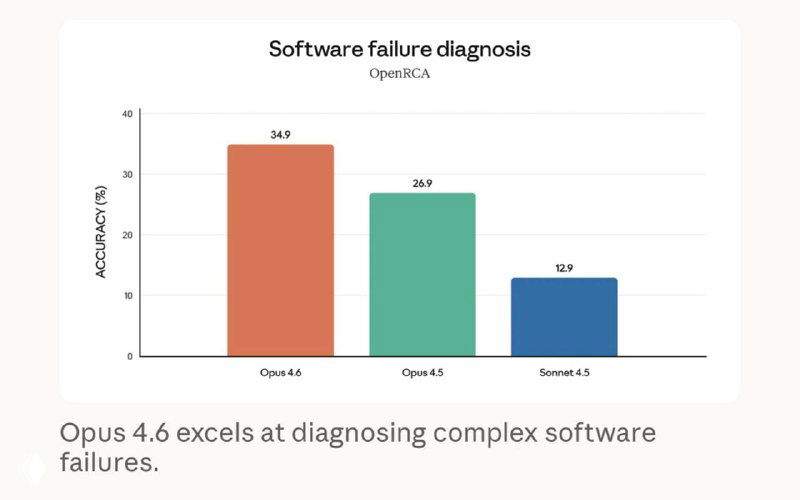
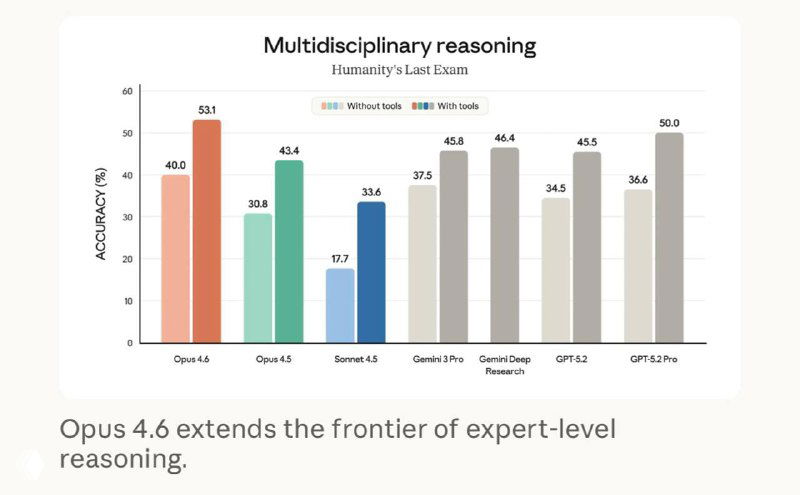
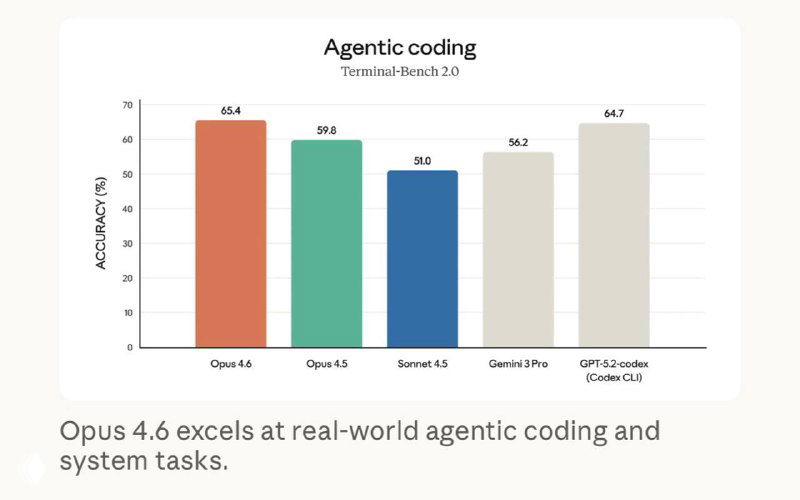
По бенчмаркам Opus 4.6 вышел в лидеры в агентном программировании (Terminal-Bench 2.0), поиске сложной информации (BrowseComp) и экономически значимых задачах знаний (GDPval-AA), где он обходит предыдущую версию и ближайших конкурентов, включая OpenAI с GPT-5.2.
Отдельно отмечают снижение деградации качества на длинных диалогах и документах — так называемого context rot.
Для разработчиков добавили уровни effort, адаптивное рассуждение и автоматическое сжатие контекста для долгоживущих агентов. Цена осталась прежней.
Модель уже доступна в интерфейсе Claude и на RouterAI.
@ai_for_devs