Она способна выполнять до 300 последовательных действий, строя цепочку логики, поиска и кода. Эта модель — очередной шаг в направлении масштабирования вычислений во время выполнения, благодаря увеличению как количества «токенов размышления», так и числа шагов при вызове инструментов.
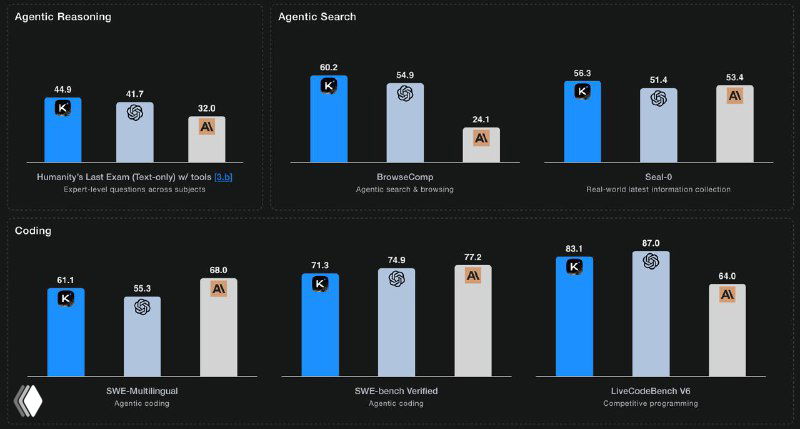
Kimi K2 Thinking устанавливает новые рекорды на бенчмарках:
- • 44,9% на Humanity’s Last Exam — топовый результат среди reasoning-моделей.
- • 60,2% на BrowseComp — лучше людей (человеческий базовый уровень: 29,2%).
- • 71,3% на SWE-Bench Verified — мощный апгрейд в агентном кодинге.
- • Поддерживает INT4-квантование без потери точности и даёт ×2 ускорение вывода.
Самый яркий пример из релиза — то, как модель создаёт сложные интерактивные приложения с нуля (можно потыкать в релизной статье). Не уверены, насколько это показательные примеры для повседневной практики разработчиков, но выглядит хорошо. Видно, что качество генераций таких MVP на очень высоком уровне.
На видео – пример результата генерации кода для популярной библиотеки визуализации.