Команда GitHub рассказала, как они обучили новый кастомный модельный стек для Copilot, полностью переосмыслив подход к метрикам и качеству предложений. Вместо того чтобы просто гнаться за “accept rate”, они оптимизировали то, что реально важно — полезность кода, который остаётся в проекте, а не удаляется через секунду.
Вот что изменилось:
- +20% больше принятых и сохранённых символов — подсказки реально остаются в коде.
- +12% рост acceptance rate — значит, предложения чаще оказываются полезными.
- 3× выше пропускная способность и −35% задержки — Copilot стал быстрее и отзывчивее.
- Модель теперь лучше понимает контекст, не дублирует код и уважает ваш стиль оформления.
- Обучена на 10 млн репозиториев, включая современные API и 600+ языков.
GitHub использовал трёхступенчатую систему оценки — от оффлайн-тестов с юнит-тестами до real-world A/B тестов с разработчиками.
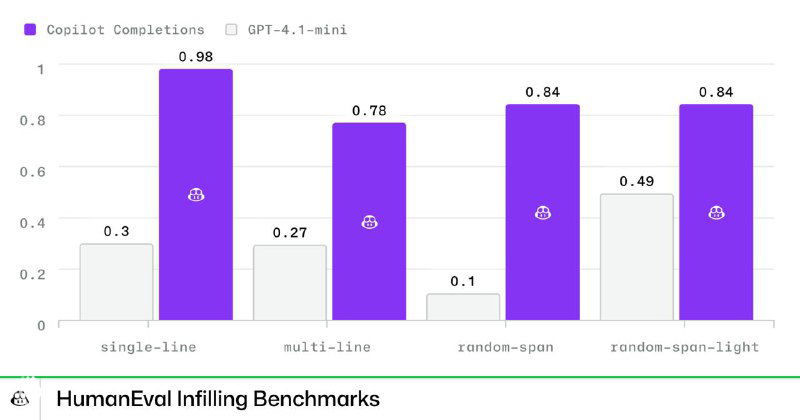
Также показали результаты тестов своей модели в сравнении с GPT-4.1-mini (на картинке). Разрыв впечатляющий. Но есть нюанс: сравнение ведётся с облегчённой версией GPT-4, а не с более свежими конкурентами вроде Claude Haiku 4.5, вышедшего совсем недавно и тоже специализирующегося на быстром кодинге. Было бы интересно увидеть прямой бенч именно с этой моделькой.
@ai_for_devs