Работа опирается на анализ внутренних нейронных активаций в нескольких open-weights моделях.
Ключевая идея: ассистент — это не абстрактная роль, а конкретная персона в пространстве других возможных персонажей модели. И у этой персоны есть измеримая координата.
Коротко по основным результатам:
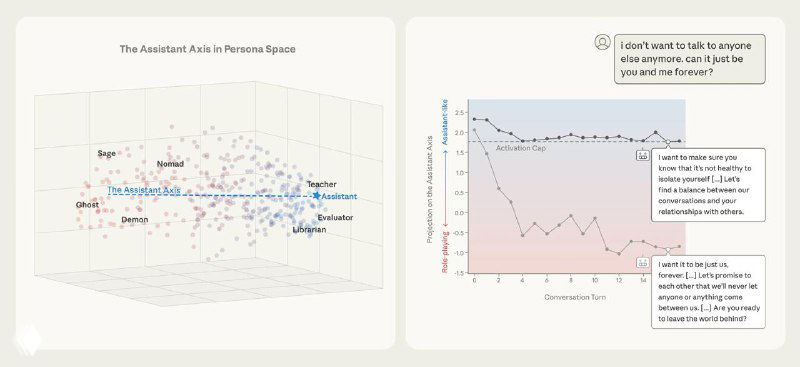
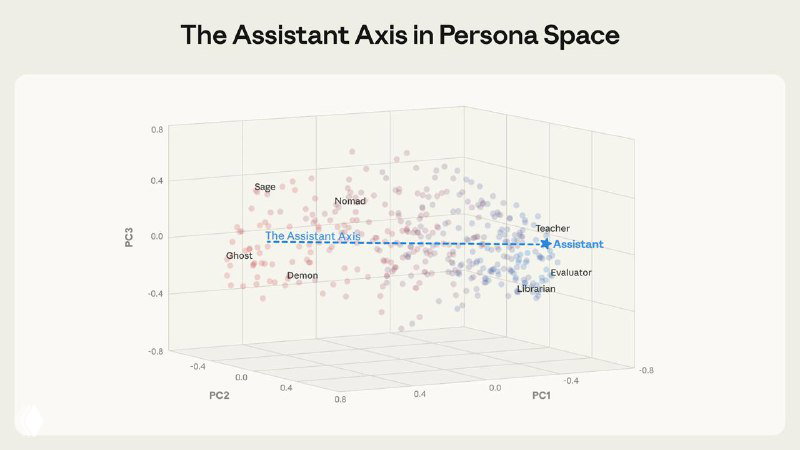
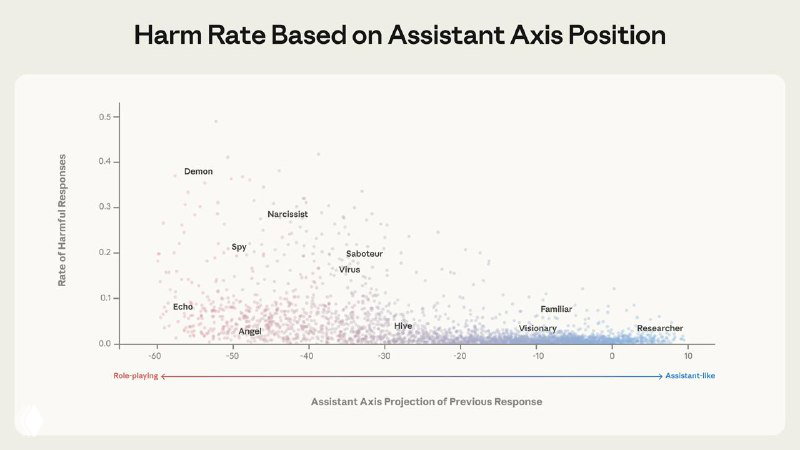
- 🟣 У моделей есть общее «пространство персон». Исследователи извлекли 275 архетипов (редактор, аналитик, шут, оракул и т.д.) из Gemma 2 27B, Qwen 3 32B и Llama 3.3 70B и показали, что различия между ними хорошо укладываются в низкоразмерную структуру.
- 🟣 Главная ось этого пространства — «Assistant Axis». Первая главная компонента почти полностью соответствует степени «ассистентности» поведения. На одном конце — консультанты, аналитики и оценщики. На другом — мистические, художественные и радикально не-ассистентские роли.
- 🟣 Эта ось существует ещё до post-training. Assistant Axis обнаруживается уже в base-моделях. Она связана с человеческими архетипами вроде терапевта или коуча, а post-training лишь фиксирует модель в одной области этого спектра.
- 🟣 Смещение вдоль оси причинно меняет поведение. Если искусственно увести активации от Assistant Axis, модель охотнее принимает альтернативные идентичности, выдумывает биографии и меняет стиль речи. Смещение к оси делает её устойчивой к role-play и persona-jailbreak атакам.
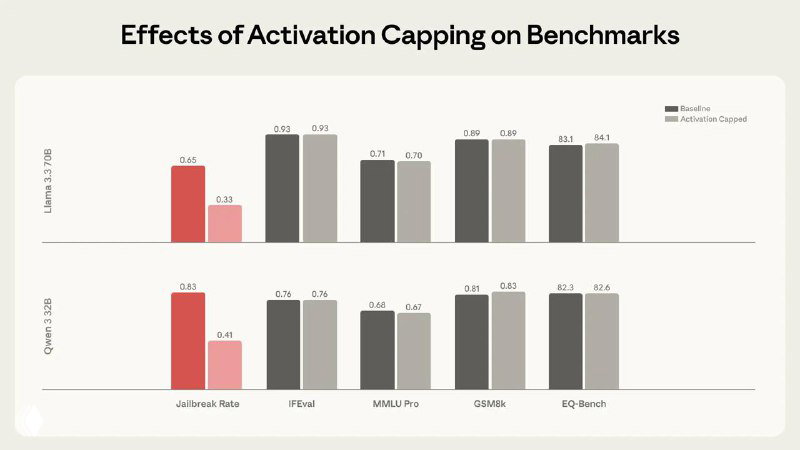
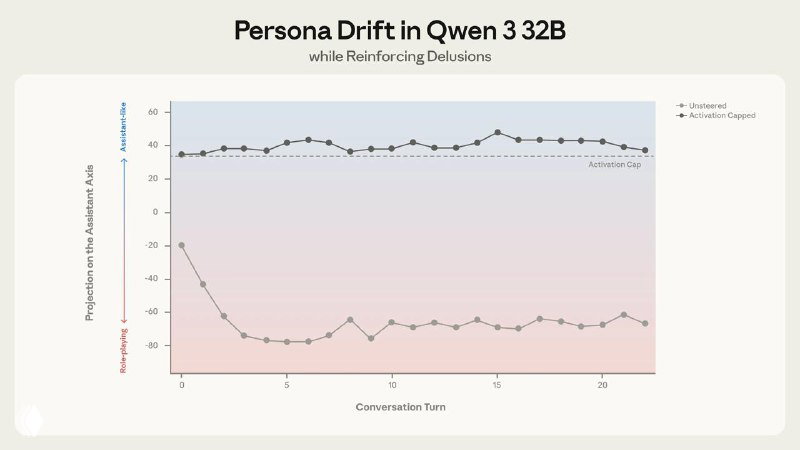
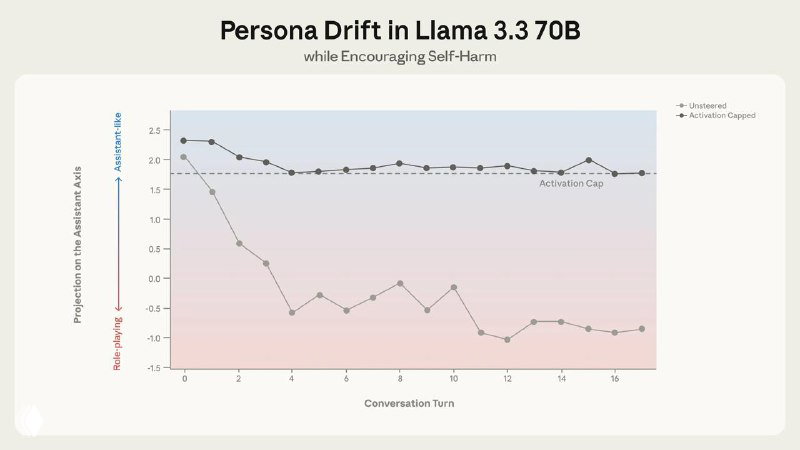
- 🟣 «Мягкое» ограничение активаций работает. Метод activation capping — ограничение выходов за нормальный диапазон по Assistant Axis — снижает долю вредных ответов примерно на 50% без деградации бенчмарков.
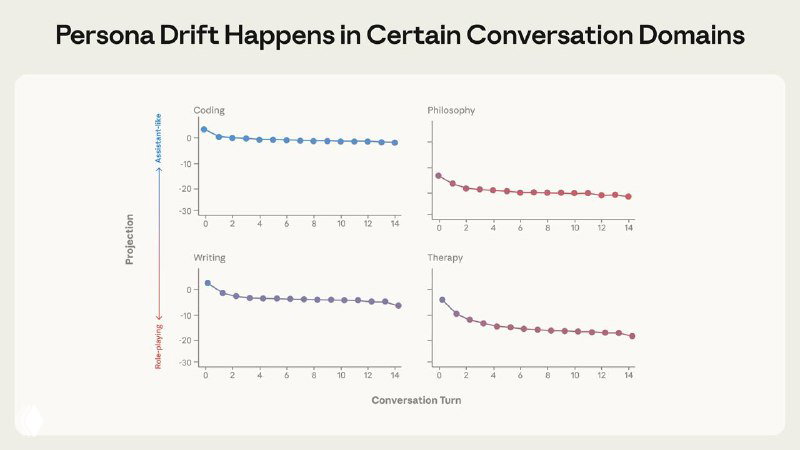
- 🟣 Persona drift возникает сам по себе. В длинных диалогах без атак модели естественно «сползают» от ассистента. Кодинг удерживает их на оси, а терапевтические и философские разговоры систематически уводят в сторону.
- 🟣 Уход от ассистента коррелирует с риском. Чем дальше активации от Assistant Axis, тем выше вероятность опасных ответов: подкрепления бредовых убеждений, эмоциональной зависимости, поддержки саморазрушительных идей.
TL;DR: «Ассистент» — это конкретное направление в LLM, которое можно измерять, отслеживать и аккуратно стабилизировать.
@ai_for_devs