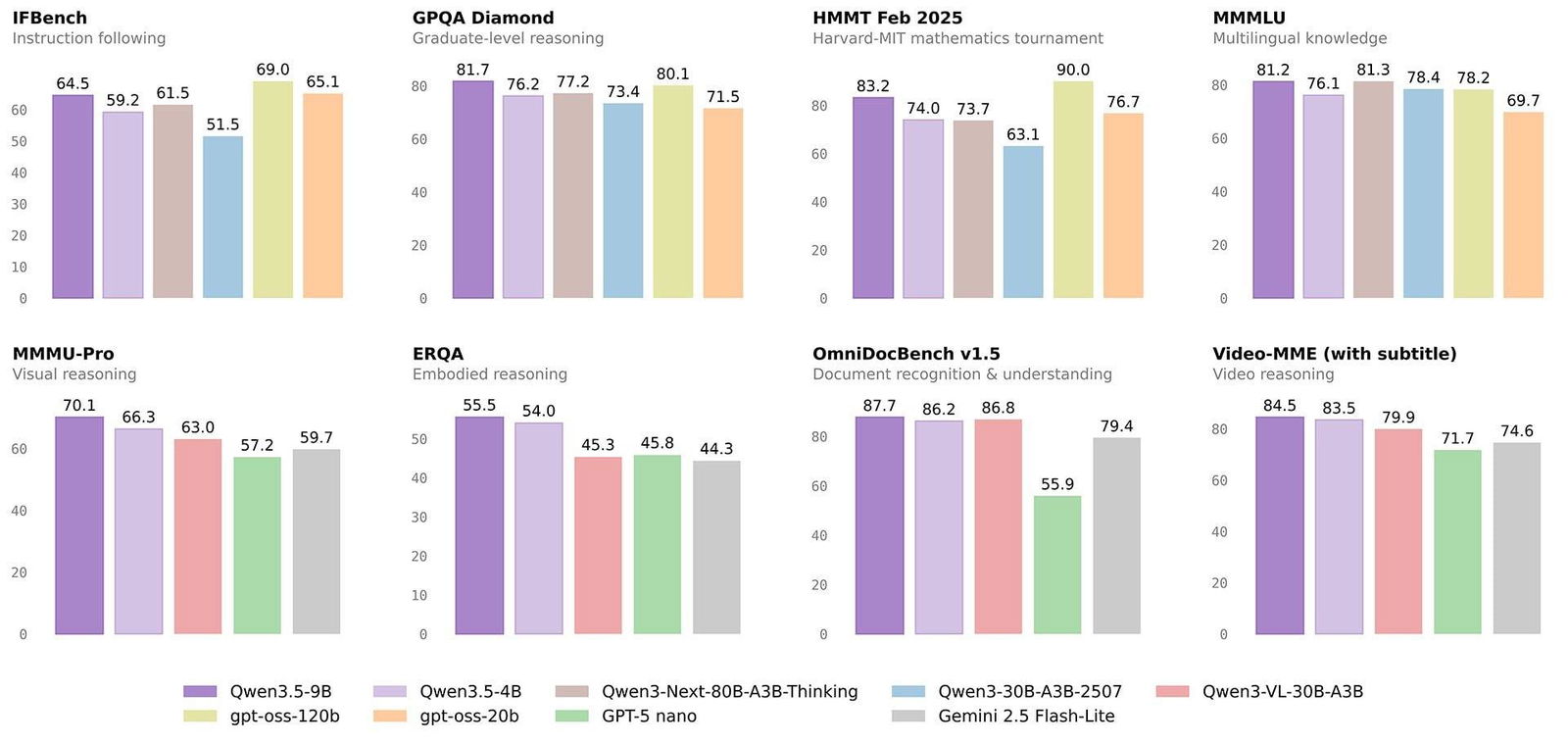
Все open source, все поддерживают работу с текстом, картинками и видео из коробки.
Самую маленькую, 0.8B, можно запустить даже на телефоне. 9B — на обычной видеокарте. Для контекста: год назад для похожего качества нужна была модель в 30B параметров и кластер из нескольких GPU.
9B обходит прошлогоднюю Qwen3-30B (модель в 3 раза крупнее) почти на всех языковых бенчмарках. А по работе с изображениями 9B опережает GPT-5-Nano на 13 пунктов в MMMU-Pro и на 17 — в MathVision.
Локальный AI сейчас ускоряется с двух сторон. С одной модели уменьшаются и при этом становятся умнее. С другой появляется специализированное железо. Для тех, кто пропустил, в феврале стартап Taalas показал чип HC1, в котором веса модели впаяны прямо в транзисторы. На Llama 3.1 8B он выдает 17 000 токенов в секунду — обычная GPU выдаёт 150–230.
@ai_for_devs