FutureX проанализировали прогнозы 25 языковых моделей с 20 июля по 3 августа 2025 года. Ответы нейросетей сравнивали не только между собой, но и с ответами 40 экспертов
Исследователи отобрали 195 сайтов и при помощи собственной LLM ежедневно извлекали оттуда события и факты. После фильтрации событий (например, субъективных) нейросетям задавали вопросы четырёх уровней сложности:
- базовый — закрытые вопросы, мало вариантов ответов
- широкий поиск — закрытые вопросы, много вариантов ответов
- глубокий поиск — открытые вопросы, низкая волатильность
- супер-агент — открытые вопросы, высокая волатильность
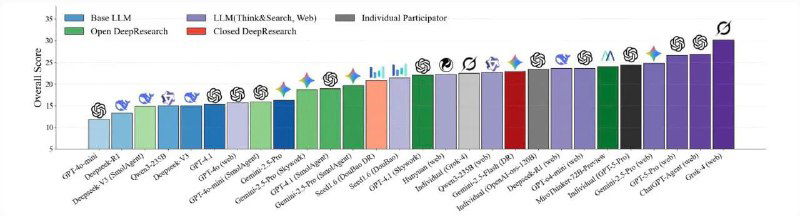
На графике — получившийся рейтинг LLM. В лидерах Grok-4, две модели от OpenAI и Gemini-2.5-Pro
Главные выводы из исследования:
- модели с поиском и рассуждением на уровнях посложнее показывали результаты лучше, чем базовые модели
- в финансовых вопросах по S&P500 лучшие модели получили больше баллов, чем аналитики Уолл-стрит, в 33-37% случае
- на первом и втором уровнях сложности Grok-4 догонял или перегонял людей
Дискуссия